前言
本系列部落格文章將分享我在 Coursera 上台灣大學林軒田教授所教授的機器學習技法(Machine Learning Techniques)課程整理成的心得,並對照林教授的投影片作說明。若還沒有閱讀過 第 9 講 的碼農們,我建議可以先回頭去讀一下再回來喔!
範例原始碼:FukuML - 簡單易用的機器學習套件
我在分享機器學習基石課程時,也跟著把每個介紹過的機器學習演算法都實作了一遍,原始碼都放在 GitHub 上了,所以大家可以去參考看看每個演算法的實作細節,看完原始碼會對課程中的數學式更容易理解。
如果大家對實作沒有興趣,只想知道怎麼使用機器學習演算法,那 FukuML 絕對會比起其他機器學習套件簡單易用,且方法及變數都會跟林軒田教授的課程類似,有看過課程的話,說不定連文件都不用看就會使用 FukuML 了。不過我還是有寫 Tutorial 啦,之後會不定期更新,讓大家可以容易上手比較重要!
熱身回顧一下
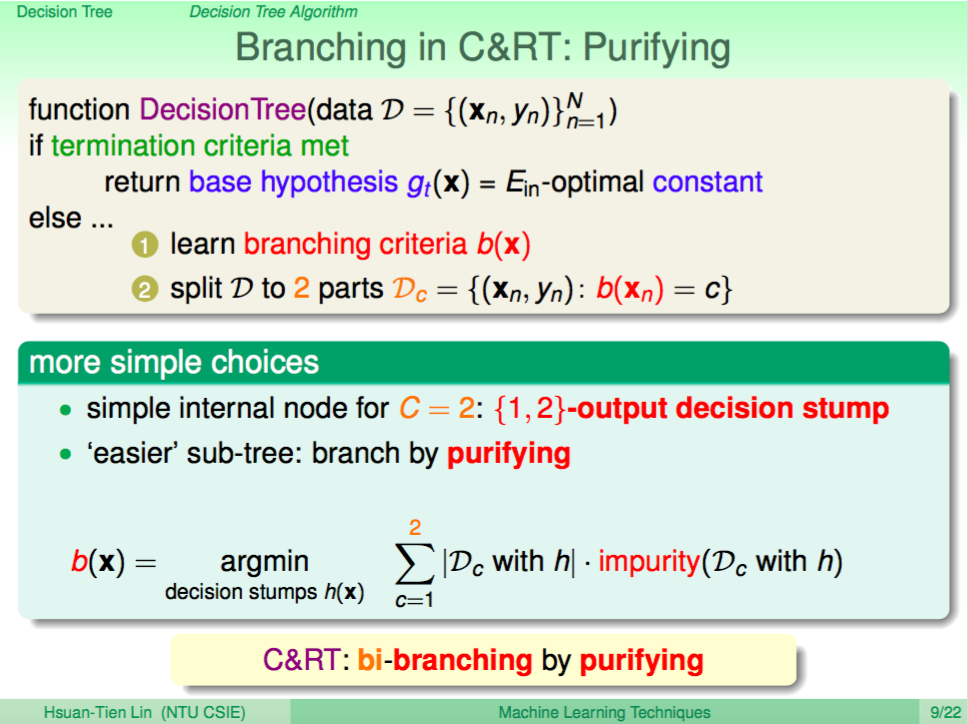
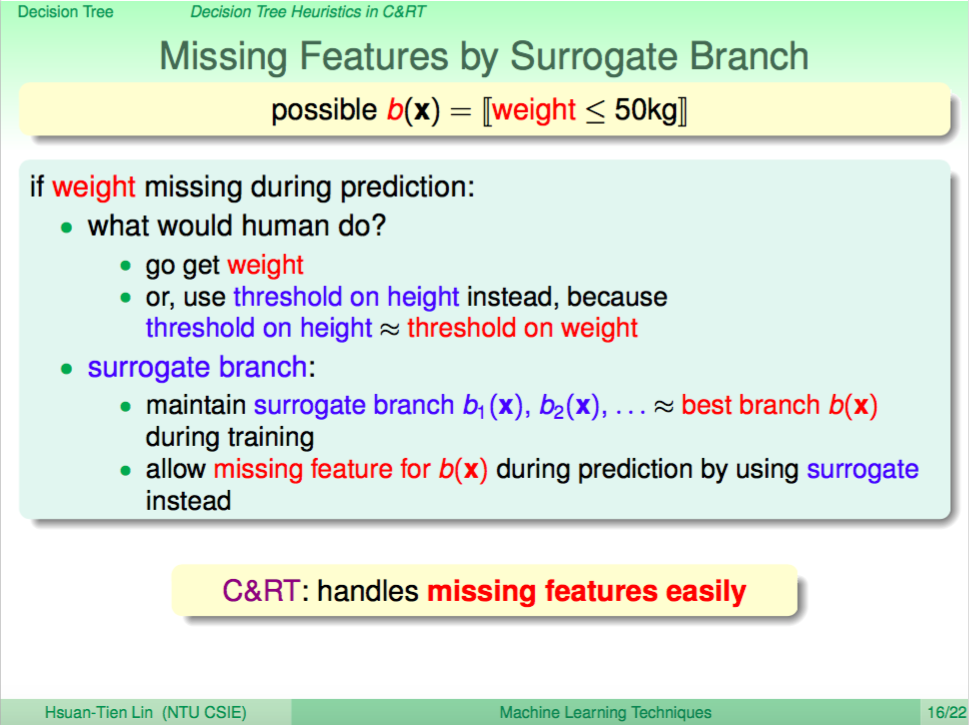
上一講介紹了 Decision Tree,如同之前介紹的 blending 算法,我們也可以進一步使用在 Decision Tree,這就是這一講要介紹的 Random Forest。

回憶 Bagging 與 Decision Tree
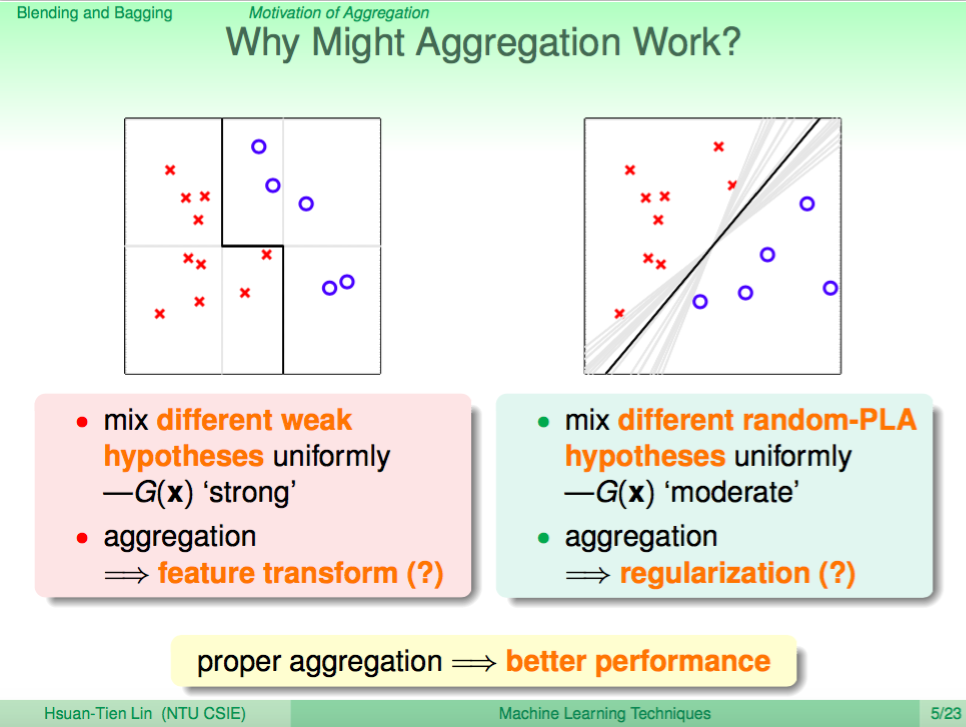
回憶一下 Bagging 與 Decision Tree 的特點,Bagging 的結合 weak learner 的方式主要是為何減少差異化,讓未來的預測可以更好,Decision Tree 結合 weak learner 的方式則是著重差異化,讓 modle 在訓練時得到的預測效果更好,我們有辦法結合這兩個特點嗎?
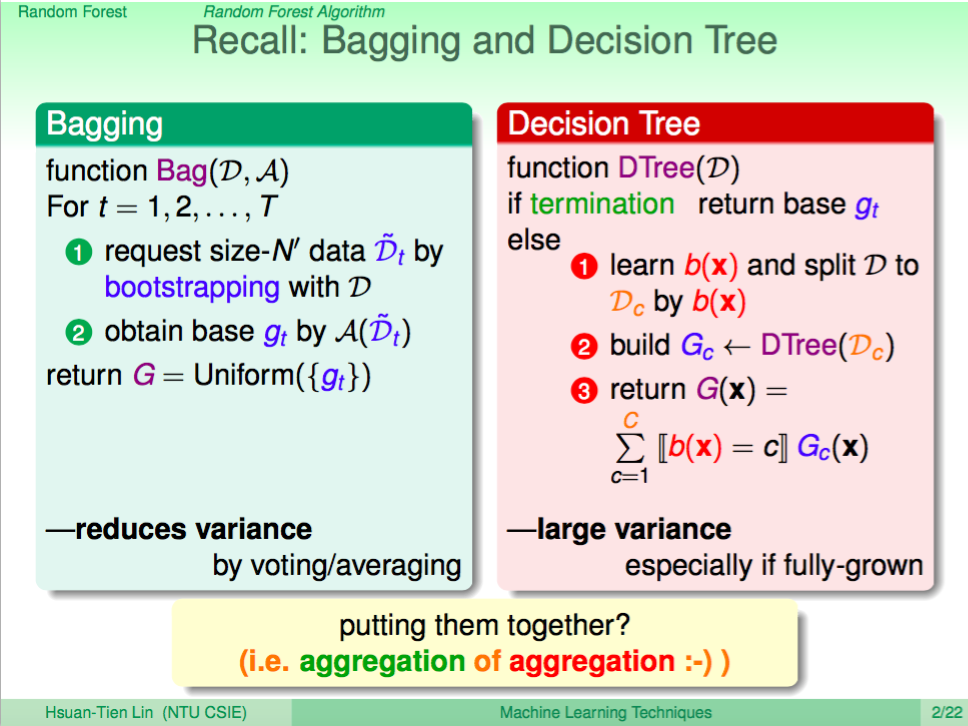
Random Forest
Random Forest 就可以達到上述的目的,每次會用類似 Bagging 的方法取得一個新的 Decision Tree,再將所有的 Decision Tree 結合起來。這個方法可以很容易地平行化運算,且不僅能夠保持 Decision Tree 的差異行,還能減少 Decision Tree 的 fully grown 的 overfitting。

透過特徵選取增加變異
Random Forest 在取得 Decision Tree 時會希望盡量取得更多不一樣的 Decision Tree,以增加分類的效果,這邊 Random Forest 的作者提出了一些方法在每次取得 Decision Tree 時過特徵選取或是特徵轉換來取得不一樣的 Decision Tree,通常會使用 low dimension 的方式進行特徵轉換,這樣運算速度可以提昇。


Bagging 在 Random Forest 的特點
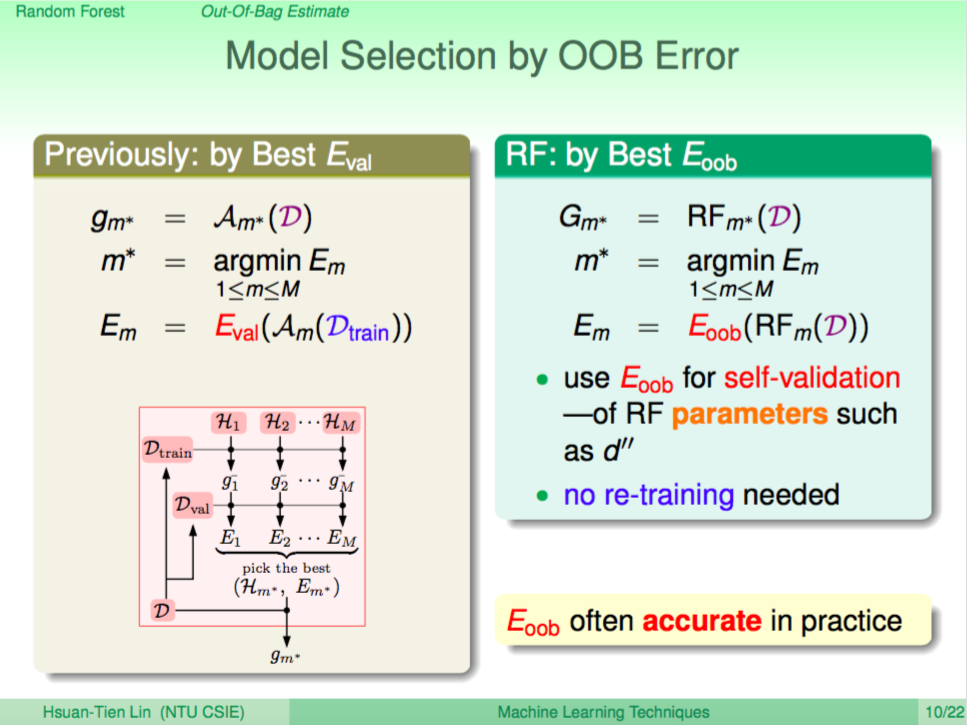
由於 Random Forest 在每一輪取得 Decision Tree 時,都會進行一下 Bagging,這時會有一些沒有被抽到的 data,這些就是 out-of-bag。

使用 Out of Bag Error 取得最後的 model
數學上證明使用 out of bag error 來取得最後的 model,未來在預測時的 error 會跟 out of bag error 非常接近,因此我們可以在訓練的過程中就順便計算 out of bag error 來進行 model 的選取。
特徵選取
Random Forest 每次選取特徵進行訓練時最簡單的方式就是隨機選取,我們也可以進一步讓演算法去根據特徵的「重要性」來進行特徵選取。

利用 Permutation Test 進行特徵選取
我們可以利用 Permutation Test 這個方法來進行特徵選取,比如 N 個樣本,每個樣本有 d 維度特徵,想要衡量其中第 i 維特徵的重要性,可以把這 N 個樣本的第 i 維特徵都洗牌打亂,再評估洗牌前跟洗牌後 Model 的 performance,如此就可以知道 i 維特徵的重要性。

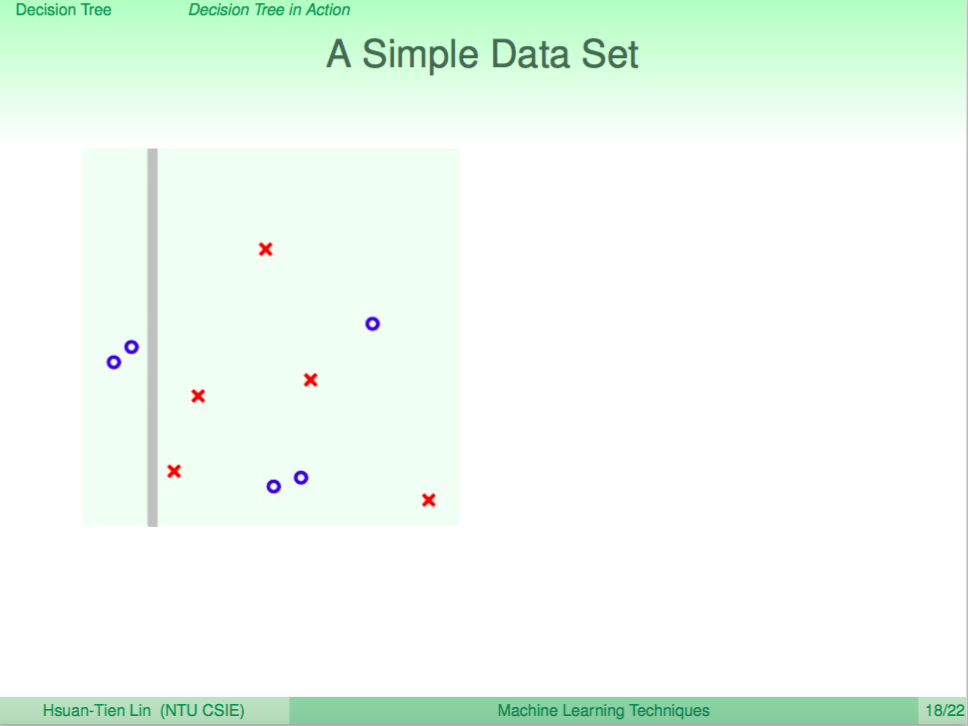
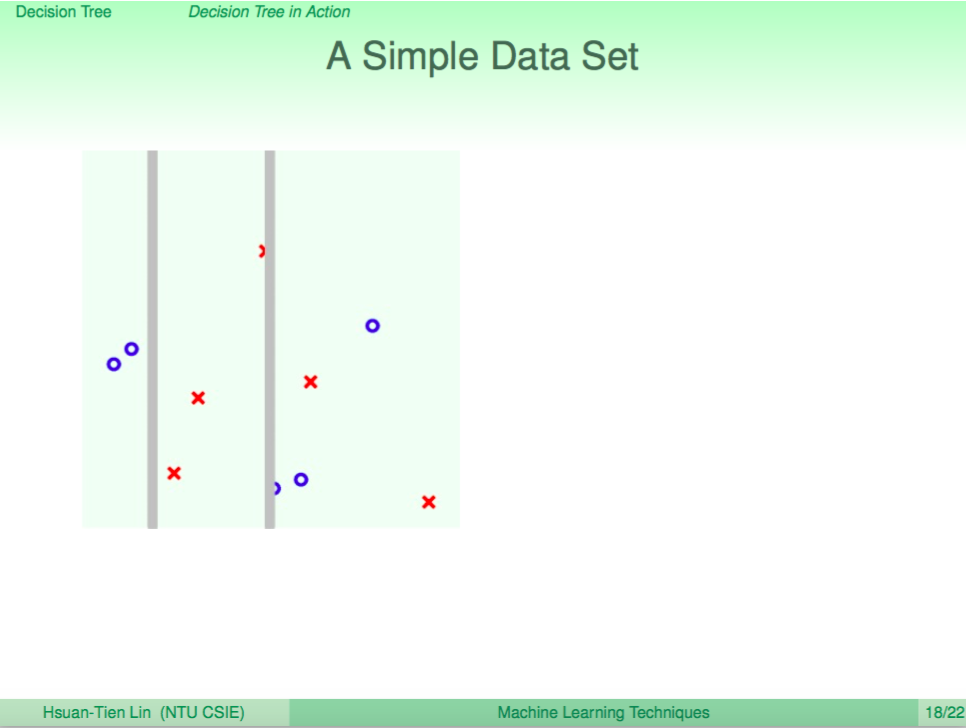
一個例子
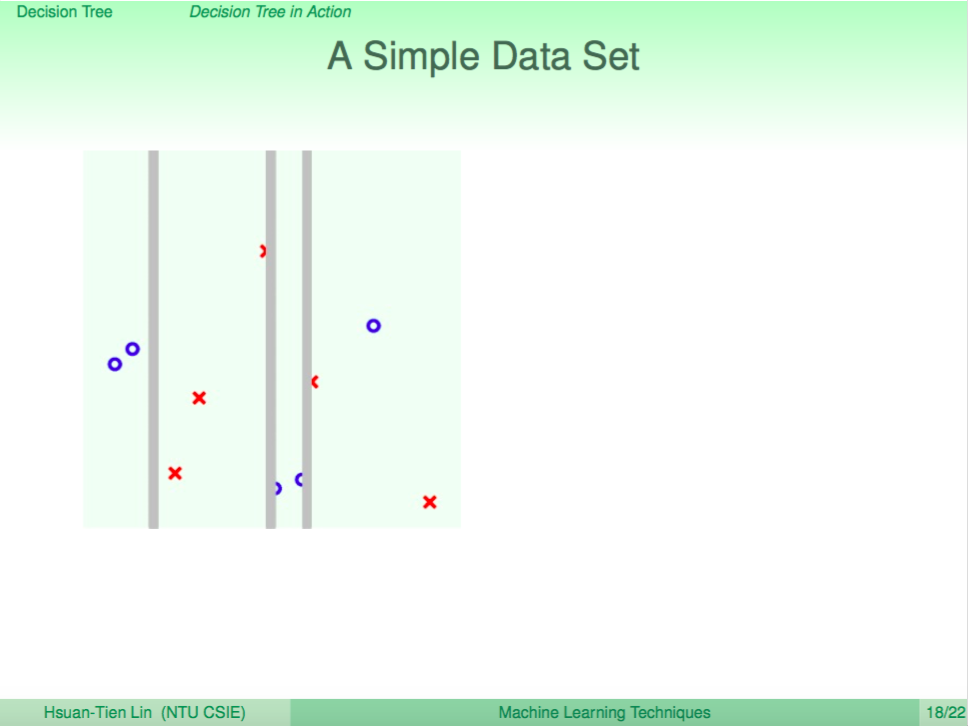
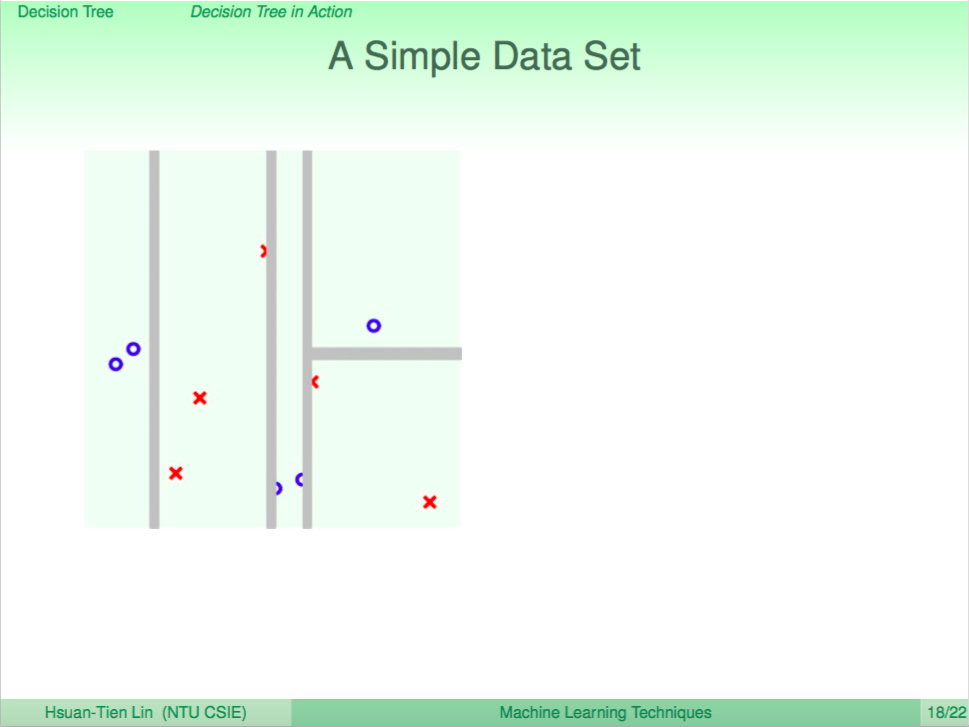
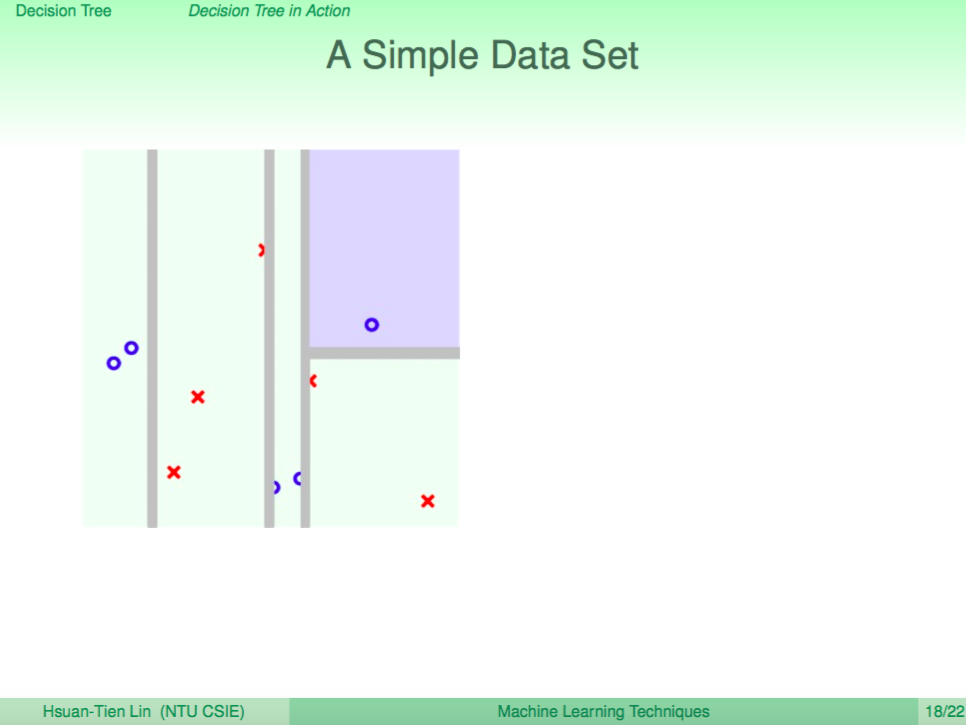
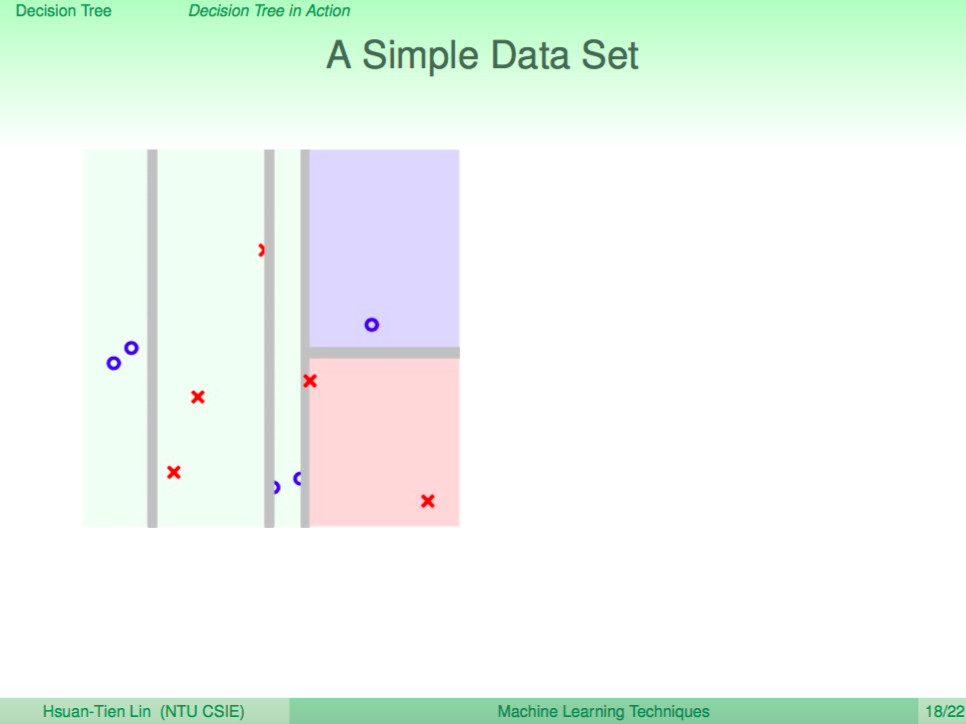
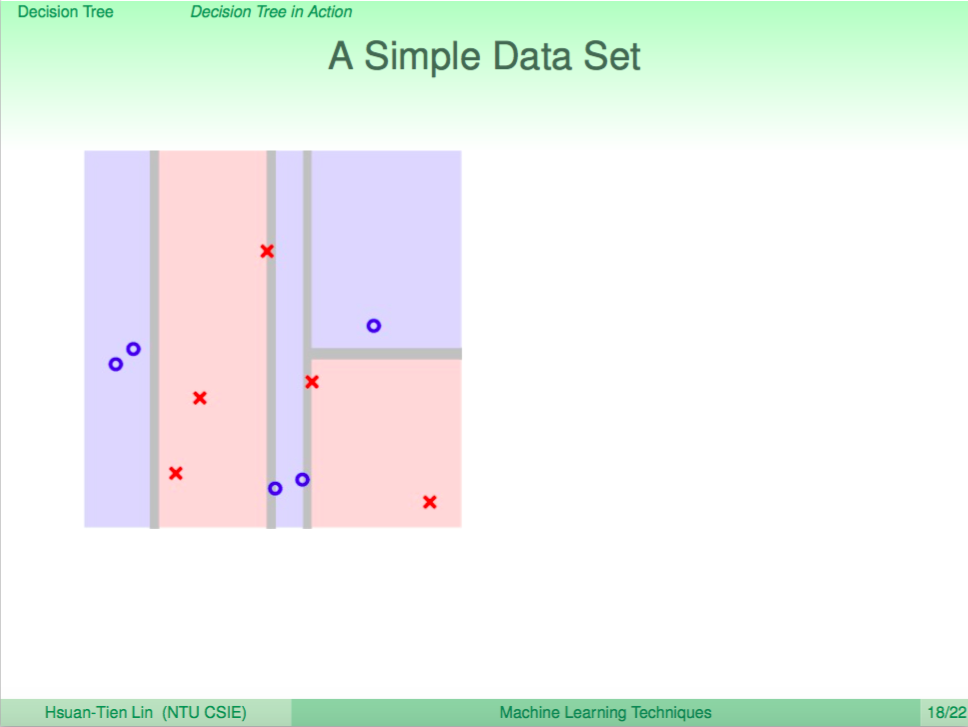
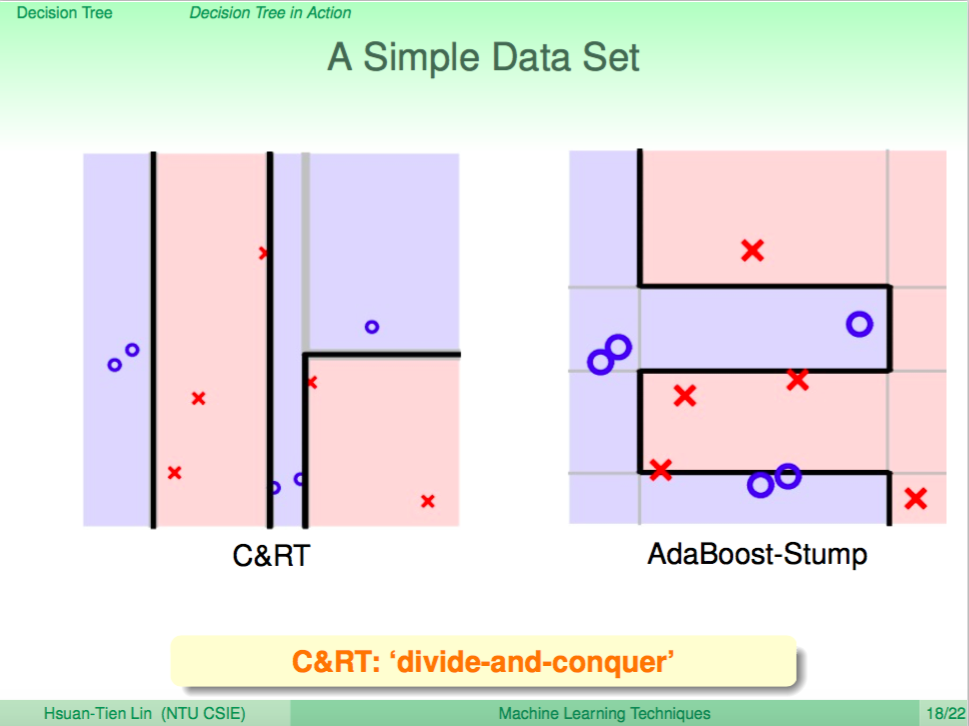
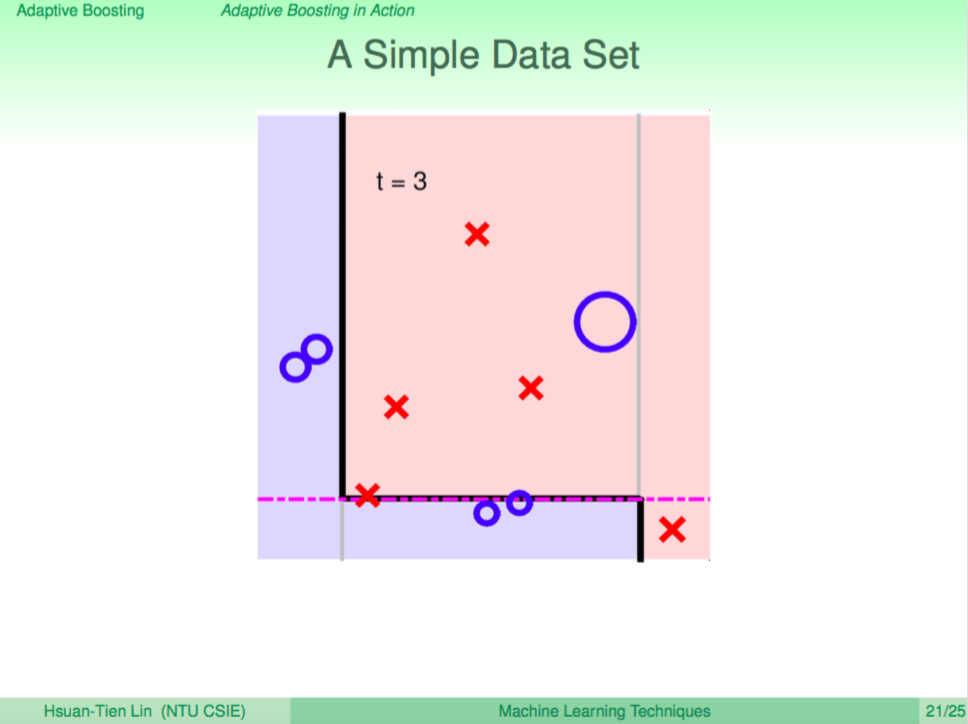
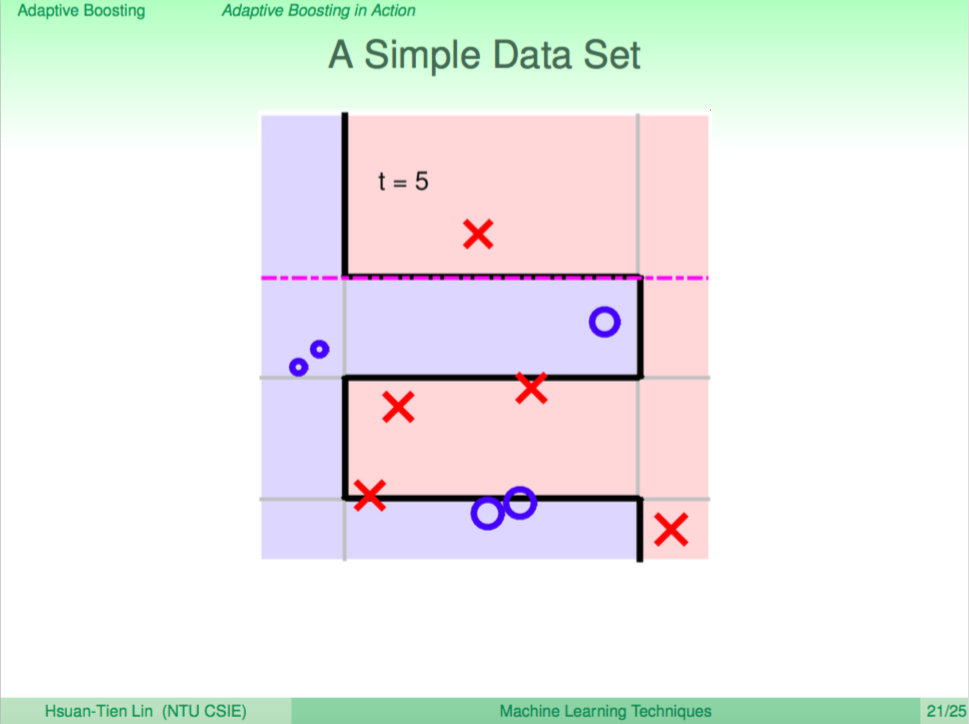
我們看一個例子,左圖是使用 Decision Tree 來做分類,右圖是使用 Random Forest 來做分類,我們可以看到 Random Forest 的邊界比較平滑。
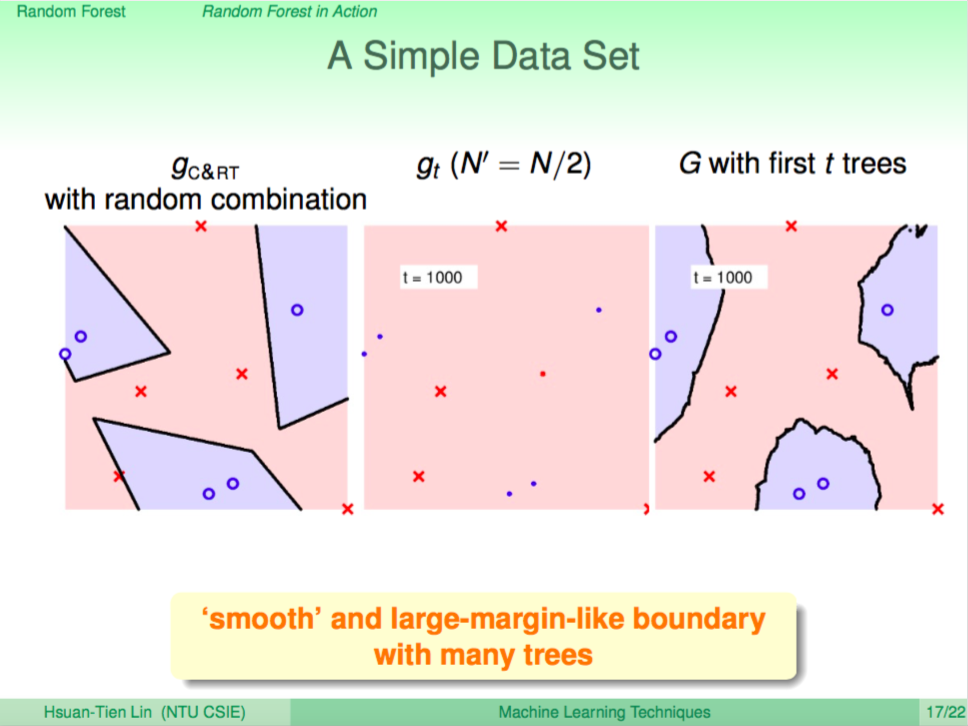
要多少棵樹呢
那訓練 Random Forest 時要娶多少棵樹呢?簡單來說就是越多棵樹越好!

總結
這一講我們介紹了 Random Forest,下一講將繼續介紹 Boosted Decision Tree。