
林軒田教授機器學習技法 Machine Learning Techniques 第 7 講學習筆記
前言
本系列部落格文章將分享我在 Coursera 上台灣大學林軒田教授所教授的機器學習技法(Machine Learning Techniques)課程整理成的心得,並對照林教授的投影片作說明。若還沒有閱讀過 第 6 講 的碼農們,我建議可以先回頭去讀一下再回來喔!
範例原始碼:FukuML - 簡單易用的機器學習套件
我在分享機器學習基石課程時,也跟著把每個介紹過的機器學習演算法都實作了一遍,原始碼都放在 GitHub 上了,所以大家可以去參考看看每個演算法的實作細節,看完原始碼會對課程中的數學式更容易理解。
如果大家對實作沒有興趣,只想知道怎麼使用機器學習演算法,那 FukuML 絕對會比起其他機器學習套件簡單易用,且方法及變數都會跟林軒田教授的課程類似,有看過課程的話,說不定連文件都不用看就會使用 FukuML 了。不過我還是有寫 Tutorial 啦,之後會不定期更新,讓大家可以容易上手比較重要!
熱身回顧一下
前 6 講我們對 SVM 做了完整的介紹,從基本的 SVM 分類器到使用 Support Vector 性質發展出來的 regression 演算法 SVR,在機器學習基石中學過的各種問題,SVM 都有對應的演算法可以解。
第 7 講我們要介紹 Aggregation Models,顧名思義就是要講多種模型結合起來,看能不能在機器學習上有更好的效果。
Aggregation 的故事
我們用一個簡單的故事來說明 Aggregation,假設現在你有很多個朋友可以預測股票會漲還是會跌,那你要選擇相信誰的說法呢?這就像我們有很多個機器學習預測模型,我們要選擇哪一個來做預測。
一個方式是選擇裡面最準的那一個人的說法,在機器學習就是使用 Validation 來做選擇。
一個方式是綜合所有人的意見,每個人代表一票,然後選擇票數最多的預測。在機器學習也可以用這樣的方法綜合所有模型的預測。
另一個方式也是綜合所有人的意見,只是每個人的票數不一樣,比較準的人票數較多,比較沒那麼準的人票數較少。在機器學習上,我們也可以為每個模型放上不同的權重來做到這樣的效果。
最後一個方式就是會依據條件來選擇相信誰的說法,因為每個人擅長的預測可能不多,有的人擅長科技類股,有的人擅長傳統類股,所以我們需要依據條件來做調整。在機器學習上也會有類似的演算法來整合各個預測模型。
Aggregation 大致就是依照上述方式來整合各個模型。

用 Validation 選擇預測模型
我們已經學過如何使用 Validation 來選擇預測模型,這個方式有一個問題就是,需要其中有一個強的預設模型才會有用,如果所有的預設模型都不準確,那也只是從廢渣裡面選一個比較不廢的而已。
所以 Validation 在機器學習上還是有一些限制的,那我們有辦法透過 Aggregation 來讓所有的廢渣整合起來,然後變強,讓預測變得更準確嗎?

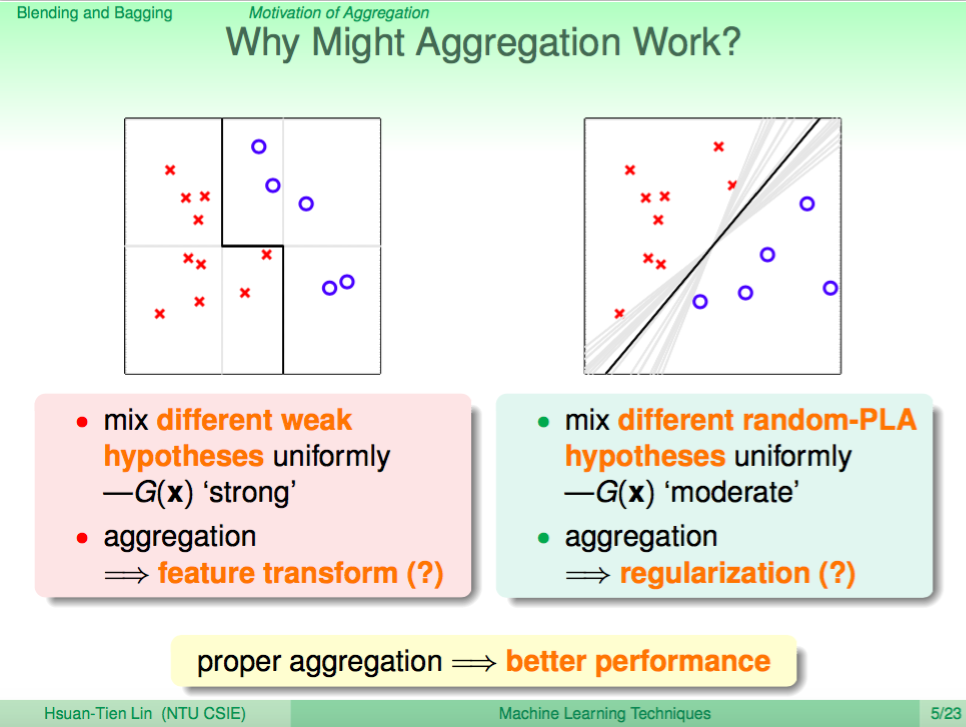
為何 Aggregation 會有用?
首先我們看左圖,如果現在預設模型只能切垂直線或水平線,其實預測效果可想而知是不會好到哪裡去的。但是如果我們將多個垂直線或水平線的預測模型整合起來,就有辦法做好一些更複雜的分類。這某種程度像是做了特徵轉換到高維度,讓預測模型變得更強、更準確。
再來我們看右圖,我們知道 PLA 因為隨機的性質,每次算出來的分類線可能會不太一樣,如果我們將所有的分類線平均整合起來,那就會得到比較中間的線,得到的線會跟 SVM 的 large margin 分類線有點類似。這某種程度就像是做了正規化,能夠避免 Overfitting。
這給了我們一個啟示,以往的學習模型,只要越強大,那就越容易發生 Overfitting,但如果越正規畫,有時可能會有 Underfitting。而 Aggregatin 卻可以一邊變強又一邊有正規化的效果。
所以適當的使用 Aggregation 的技巧是可以讓機器學習的效果更好的。
Uniform Blending 用在分類上
現在我們介紹一個最簡單的 Aggregation 方法 - Uniform Blending,在分類問題上,我們只要很單純地將所有的預測模型的預測結果加起來,然後看正負號就可以做到分類的 Uniform Blending。
這個方法要注意整合的預測模型需要有差異性,不能每個模型預測結果都是一致的,這樣就會沒有效果。

Uniform Blending 用在迴歸上
在迴歸問題使用 Uniform Blending 就是將所有預設模型的預測結果加起來,然後除上模型的個數,也就是做平均的意思,這樣就可以做到 Aggregation 了。
但同樣也要注意整合的預設模型需要有差異性才會有效果。

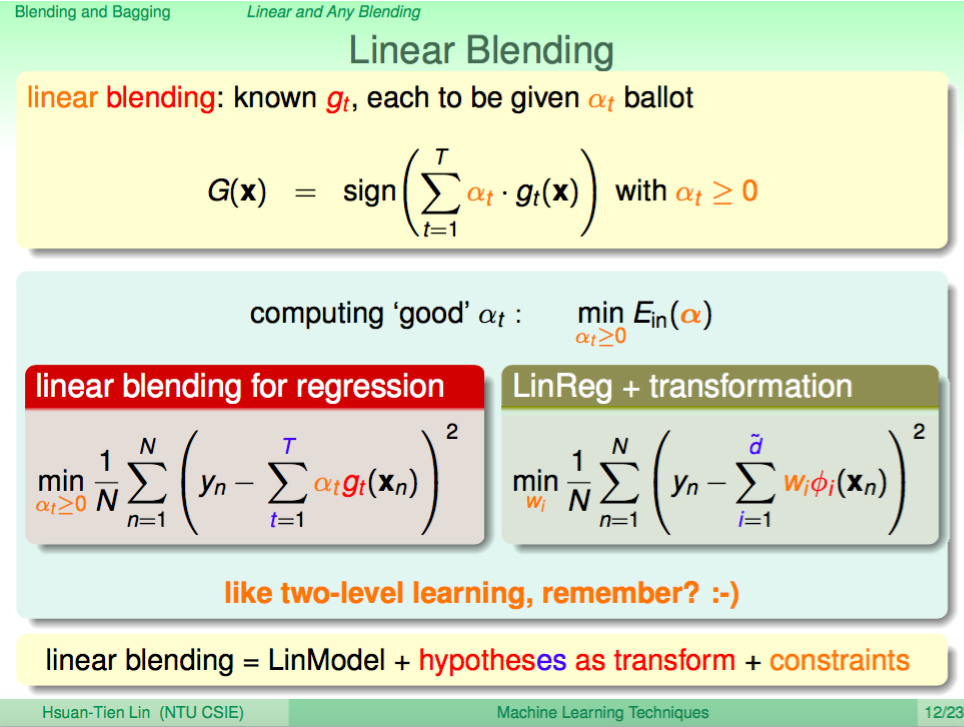
Linear Blending
Uniform Bleding 每個預測模型的是一視同仁,可能不夠強大,我們可以使用 Linear Blending 來給每個預設模型不一樣的權重,數學式如下圖所示,其中權重是大於等於 0 的。
演算法的調整方法,其實就是先將資料透過每個模型做預測當成是一種特徵轉換,然後將轉換過後的資料當成是新的資料來做訓練,再使用 Linear Regressiong 算出每個預測模型的權重。未來預測時也是用每個模型轉換過後的資料再依權重做計算。
不過數學式上的條件還有權重都要大於等於 0,這在我們目前的演算法並沒有考慮進去。
權重大於等於 0 可以忽略
在 Linear Regression 算權重時,權重可能會有小於 0 的情況,在物理意義上就代表這個模型猜得很不準,所以物理意義上就像是我們把它用來當成反指標,所以它也是對預設有幫助的。因此權重大於等於 0 這個條件我們可以忽略,

差異化的模型
目前我們已經大致學會了幾種 Aggregation 的方法,都需要整合的模型之間有差異化。那我們怎麼得到有差異化的模型呢?
一個就是本來就是演算法哲學不同的模型;一個是從參數來調出差異化;而有隨機性的模型其實每次得到的預測模型也會有差異化;另外一個方式我們可以從資料面(每次訓練餵不一樣的模型)來做出模型的差異化。

Bootstrap Aggregation 資料差異化的整合
我們如何做到資料差異化的整合呢?如果我們能夠一直不斷的得到不同的 N 筆資料來做訓練,那就可以很容易地做到了。但我們手上只有原本的 N 筆訓練資料,不可能再拿到其他訓練資料,實務上我們的做法就會是從這 N 筆資料中做取後放回的抽樣抽出 N 筆資料,這樣我們每一輪都會得到不同訓練資料(由於是取後放回,N 筆資料中會有重複的資料),這樣就可以用來訓練有差異化的預測模型。
這種 Bootstrap Aggregation 也叫做 Bagging。

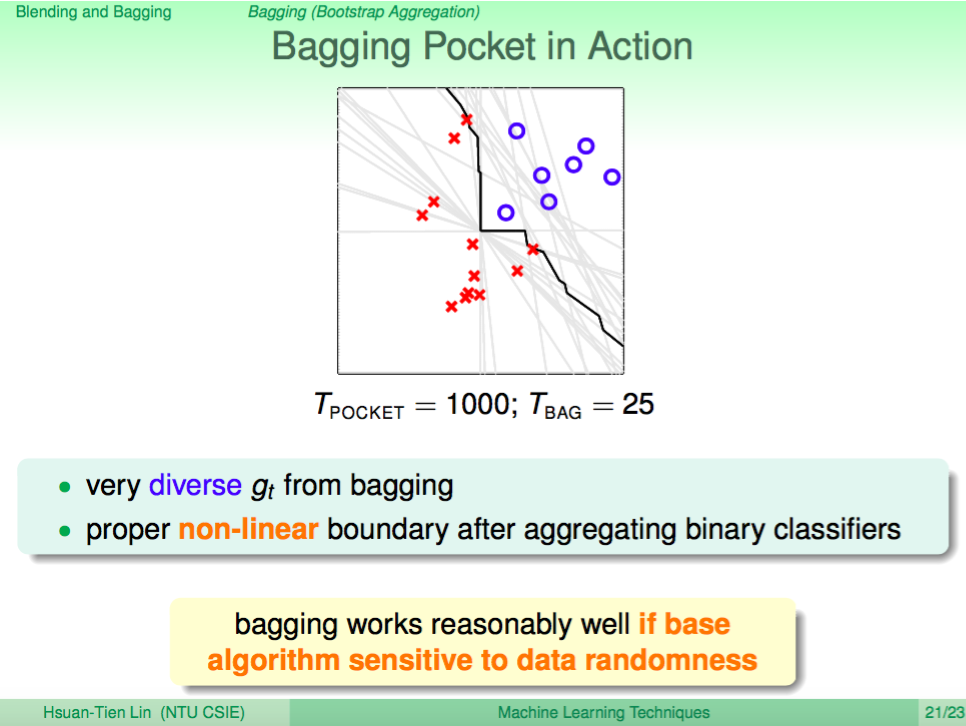
Pocket 使用 Bagging Aggregation 的效果
下圖是 Pocket 使用 Bagging Aggregation 的實例效果,可以看出每個分類線是有差異的,而整合起來又有非線性分類的效果,Bagging 這個方法在有隨機性質的算法上理論上都是有用的。
總結
這一講就是介紹如何整合很多個預測模型的預測結果,理論上是可以帶來更好的效果的,所以如果訓練出來的模型都是廢渣的話,也許用 Aggregation 的技巧就會讓效果變好。


