前言
本系列部落格文章將分享我在 Coursera 上台灣大學林軒田教授所教授的機器學習技法(Machine Learning Techniques)課程整理成的心得,並對照林教授的投影片作說明。若還沒有閱讀過 第 8 講 的碼農們,我建議可以先回頭去讀一下再回來喔!
範例原始碼:FukuML - 簡單易用的機器學習套件
我在分享機器學習基石課程時,也跟著把每個介紹過的機器學習演算法都實作了一遍,原始碼都放在 GitHub 上了,所以大家可以去參考看看每個演算法的實作細節,看完原始碼會對課程中的數學式更容易理解。
如果大家對實作沒有興趣,只想知道怎麼使用機器學習演算法,那 FukuML 絕對會比起其他機器學習套件簡單易用,且方法及變數都會跟林軒田教授的課程類似,有看過課程的話,說不定連文件都不用看就會使用 FukuML 了。不過我還是有寫 Tutorial 啦,之後會不定期更新,讓大家可以容易上手比較重要!
熱身回顧一下
上一講我們介紹了 Adaptive Boosting 這種可以結合多個 Weak Learner 的 Linear Aggregation Model,這一講將介紹另一種 Aggregation Model - Decision Tree,Decision Tree 其實就是一種 Non-Linear 的 Aggregation Model。
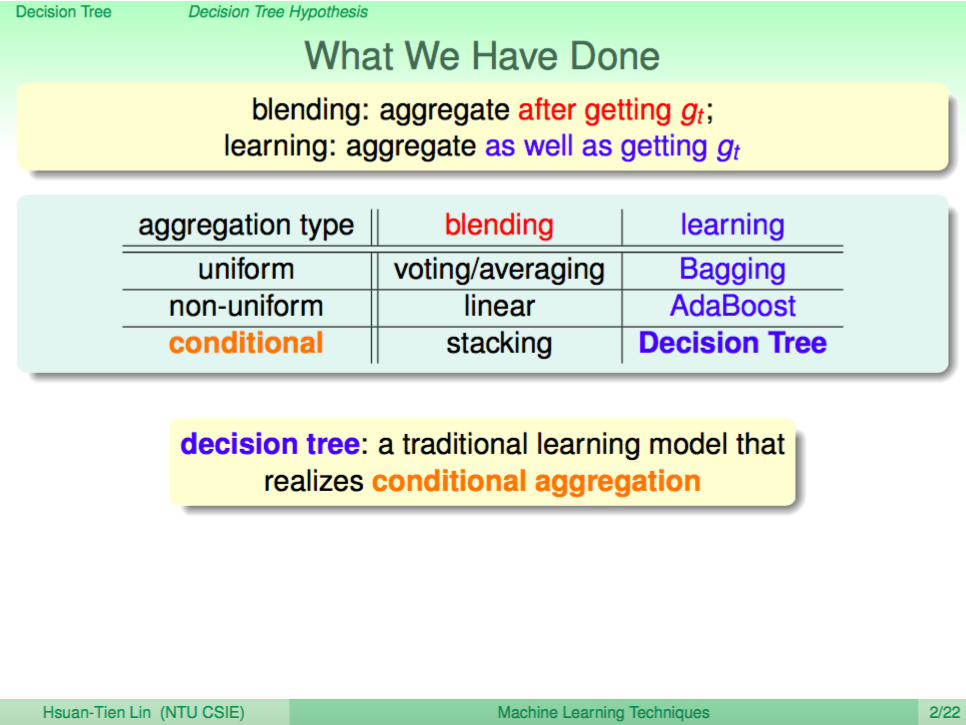
Aggregation Model 表格
我們可以將這幾講種所介紹的 Aggregation Model 用這個表格整理出來,我們可以知道 AdaBoost 跟 Decision Tree 都是 Weak Learner Aggregation 的模型,只是 AdaBoost 是 Linear Aggregation,會讓所有的 Weak Learner 一起發揮作用,但 Decision Tree 則是 Non-Linear 的 Conditional Aggregation,會每次根據 condition 讓某個 Weak Learner 發揮作用。
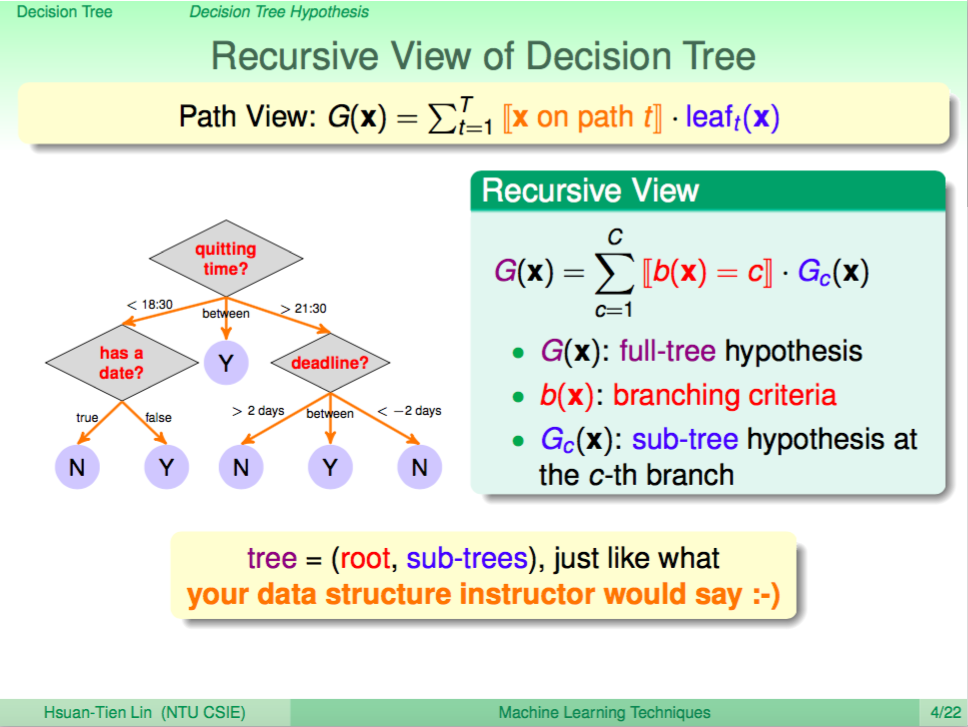
Decision Tree 遞迴式
Decision Tree 的內涵其實就是去模仿人類的決策過程,我們可以用底下這個樹狀圖說明,人類簡化的決策過程大致就是依據很多種情況及條件,最後才去下決定。Decision Tree 會根據訓練資料去長成符合訓練資料所下決定的樹狀圖,而數學式可以用一個遞迴式來表示,父節點就是由分支條件及子樹所組成,我們可以遞迴地分支下去。
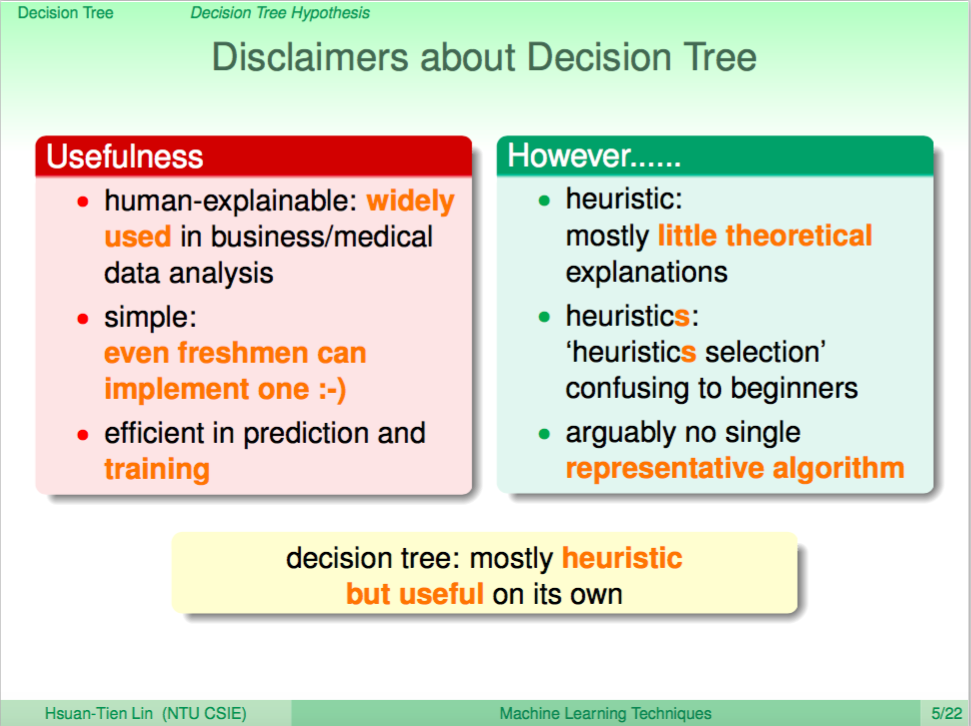
Decision Tree 的特點
由於 Decision Tree 大體上的內涵就是想要模仿人類決策的過程,因此模型也會比較具有解釋性,我們可以從模型中了解當某個指數(特徵值)高於多少時可能會有什麼結果,比起 SVM 我們很難解釋是哪個特徵值影響了分類結果,所以 Decision Tree 在直接面對客戶的產業上如商業及醫藥上運用也較為廣泛。
但 Decision Tree 有個缺點就是沒有什麼完備的理論保證,各種 Decision Tree 的發明都有演算法各自的小巧思,也難說哪種 Decision Tree 的表現會比較好。
Decision Tree 基礎演算法
根據剛剛說的遞迴式我們可以大致寫出 Decision Tree 的基礎演算法如下:
輸入 N 個樣本點,如果分支達到條件(無法再分支),就回傳 gt(x),如果還沒達到條件就繼續:1. 獲得分支條件 2. 根據分之條件將資料分成 C 份 3. 由這 C 份資料生成 C 棵子樹 4. 將 C 顆子樹及分支條件一起回傳。

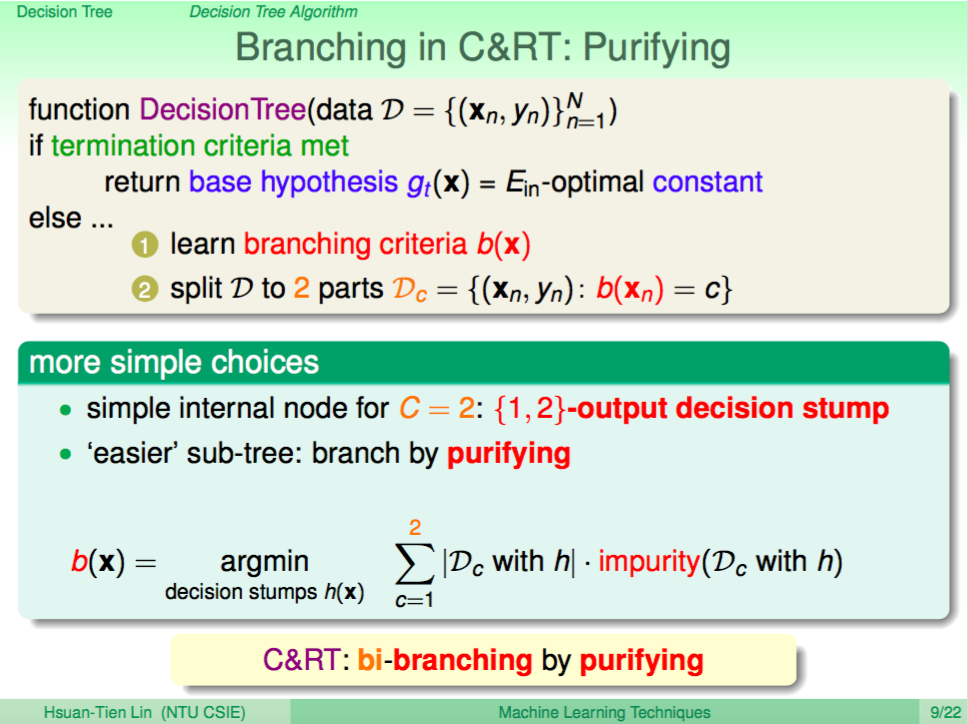
CART 演算法
只要符合 Decision Tree 的基礎演算法都是一種 Decision Tree 演算法,我們這邊要介紹的是 CART 這種 Decision Tree。
CART 的特點就是可以同時處理分類及迴歸的問題,而演算法的細節就是每次進行分支的時候會將資料分成兩份,也就是 Binary Tree。然後選擇分支條件的準則就是經過這個分支後底下的子樹資料變得更「純」了。

CART 分支判斷:純不純
CART 分支判斷我們是使用子樹資料變得更「純」了來做判斷,在演算法訓練的過程中我們會反過來計算純度,所以會使用代表不純度 impurity 的函式來做計算,我們需要找出不純度最低的分支。
Impurity 函式
那麼 Impurity 如何計算呢?根據不同的問題我們可以設計不同的 impurity 函式,如果是迴歸問題,CART 用均方差來衡量,如果是分類問題,CART 用 Gini Index 來衡量(子樹都是同一類的話,Gini Index 為 0,即不純度為 0)。

終止條件
CART 的終止條件有兩種情況:1. 如果 impurity 為 0,那代表子樹只剩下相同的分類資料了,所以就不用再分下去了 2. 如果所有的 xn 都相同了,也就是所有資料的 xn 特徵值都相同,也就沒有辦法劃分了。

CART 詳細演算法
綜合上述 CART 的設計巧思,我們可以把 CART 的詳細演算法表示成下圖,CART 只要做一些些小小的修改就可以很方便處理二元分類、多元分類、迴歸問題,但我們現在的算法會長成一個完全成長樹,因此會有 overfitting 的問題。

使用 Pruning 正規化
CART 設計了 Pruning(剪枝)這個方法來處理 overfitting 這個問題,每次去除一個葉子,然後看看剪去哪個葉子時 Ein 最小。

枚舉特徵的處理
然後 CART 在處理實際情況下我們會面臨到的問題,當我們的資料特徵有些並不是數值而是枚舉類型特徵(categorical features)時,CART 也可以很容易地處理這樣的特徵。

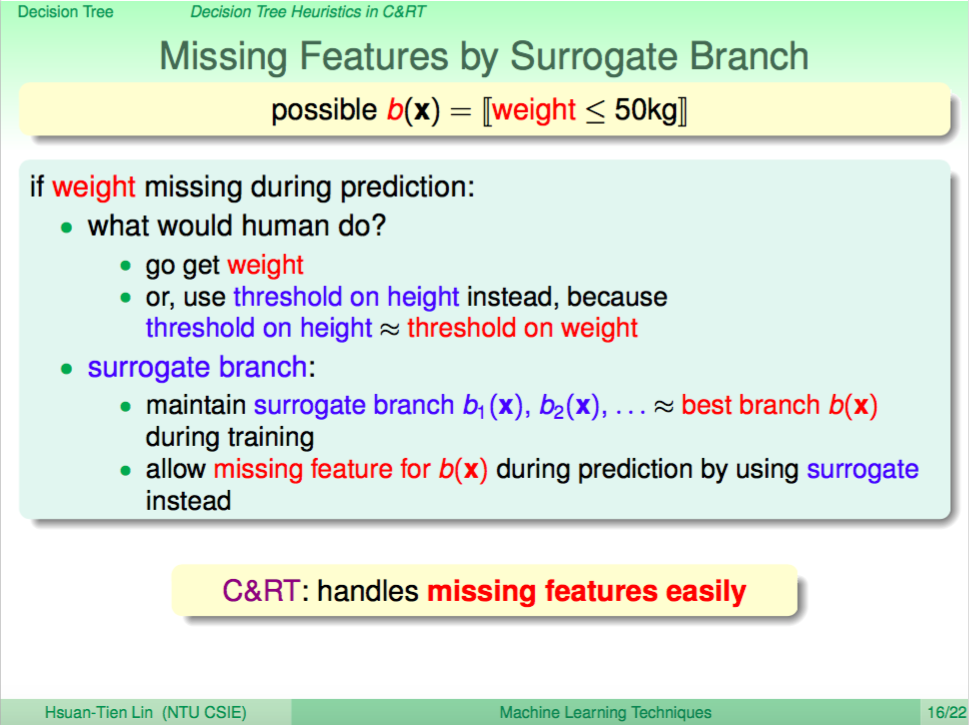
Missing Feature 的處理
有時我們的測試資料可能缺少某些特徵,CART 可以透過 Surrogate Brach 這樣的方法來處理 Missing Feature 的問題,一樣可以預測出結果。直觀的想法就是,某些特徵分支的情況可能類似,就可以使用某特特徵來替代遺失特徵的資料,由於 Decision Tree 訓練都會記下分支的結果,所以才可以做到這一點。
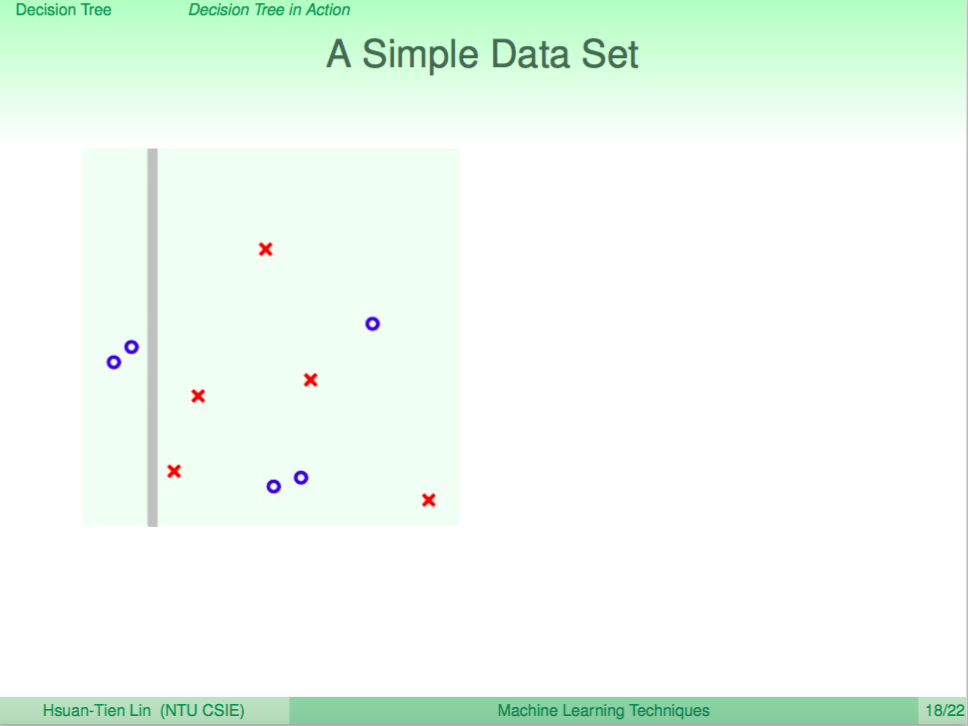
簡單的 CART 分支訓練過程範例
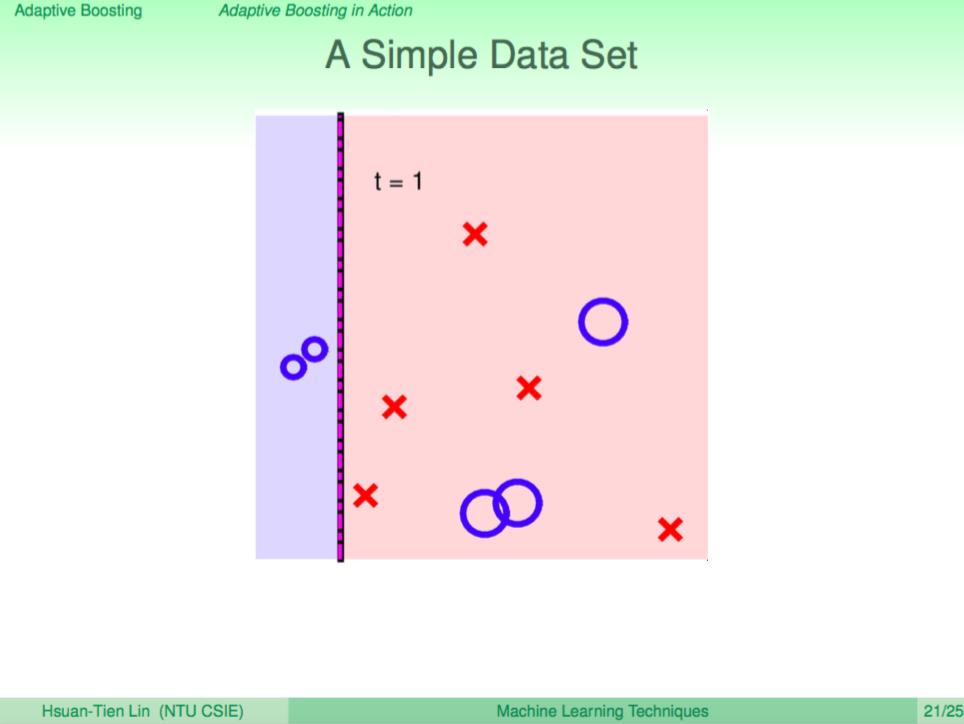
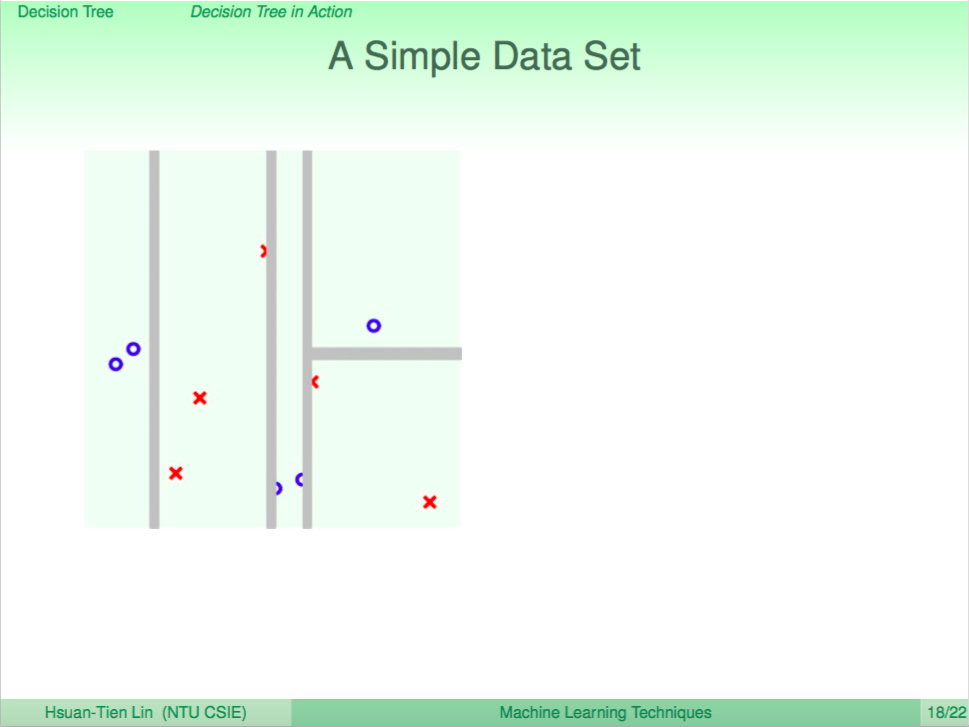
我們看一個簡單的 CART 分支訓練過程範例
每次分出一個簡單的分支
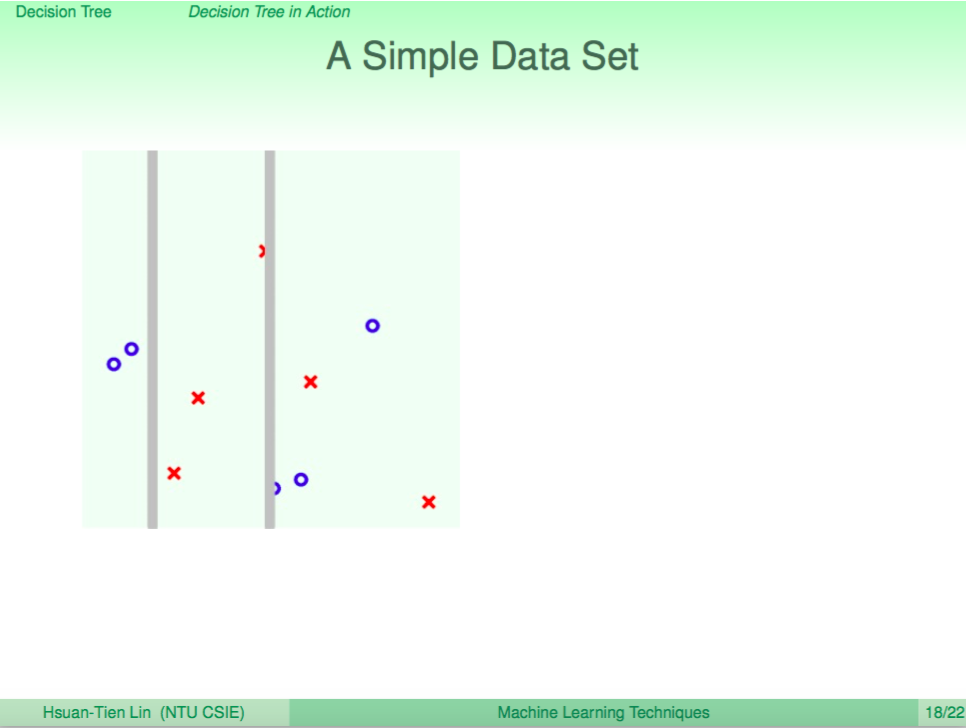
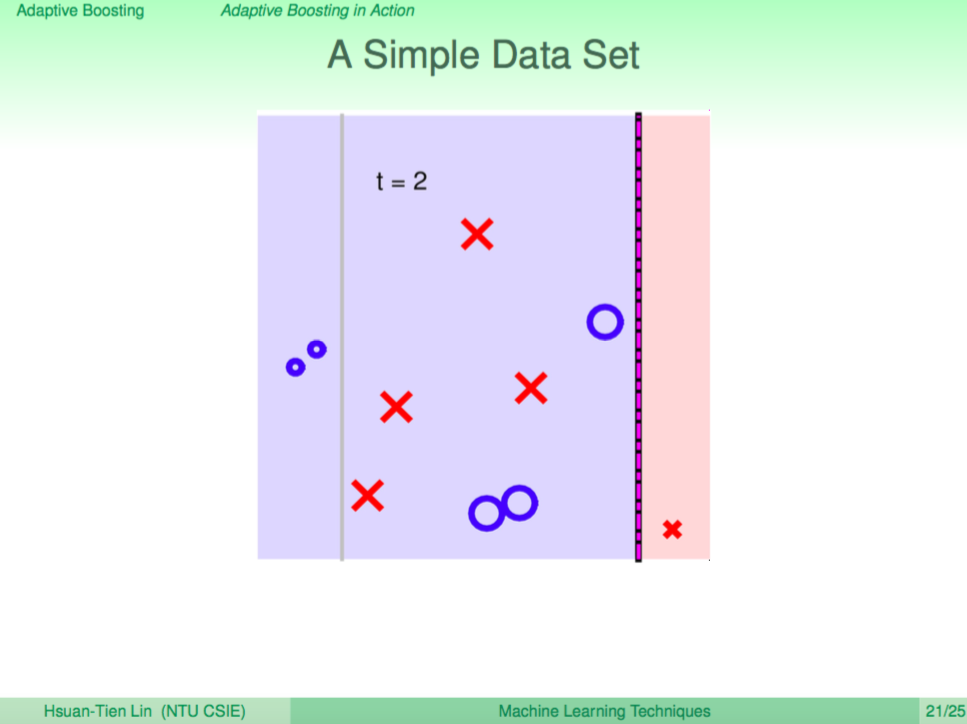
然後遞迴往下分
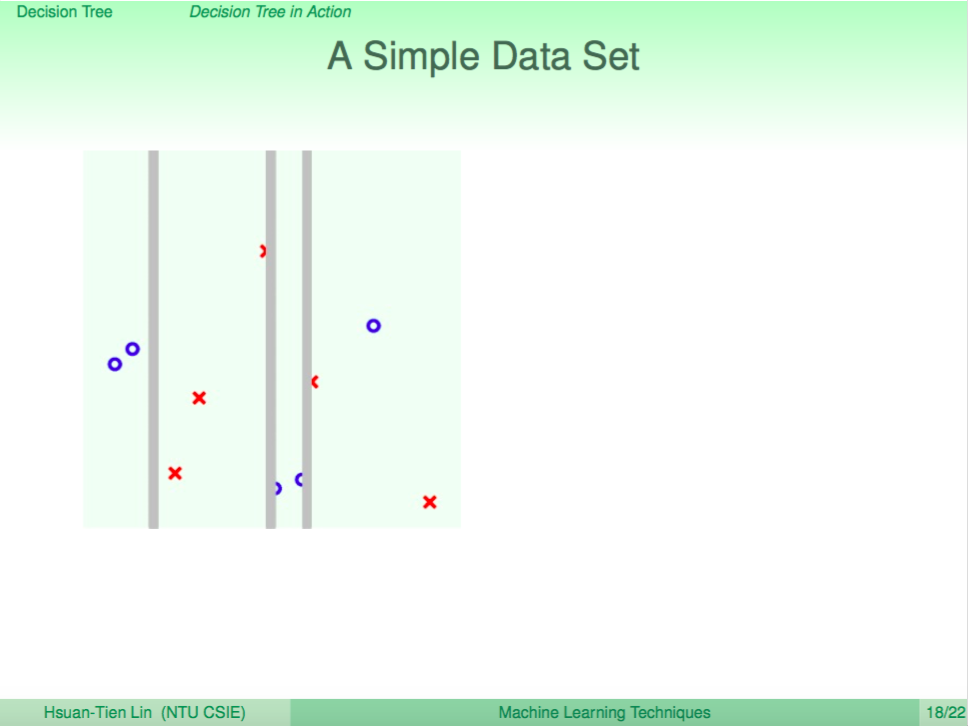
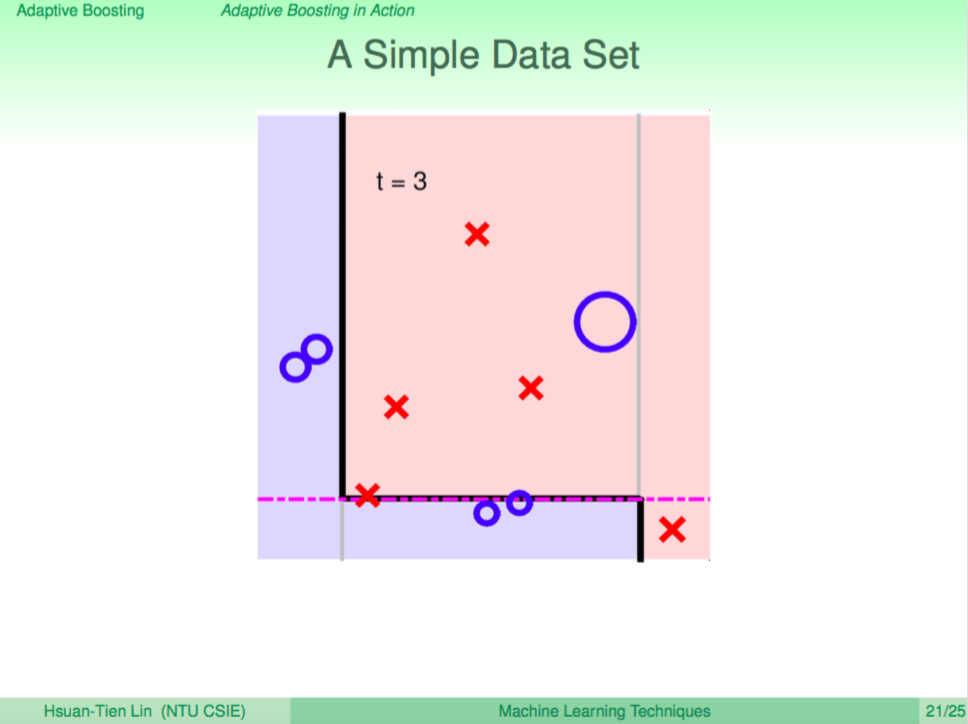
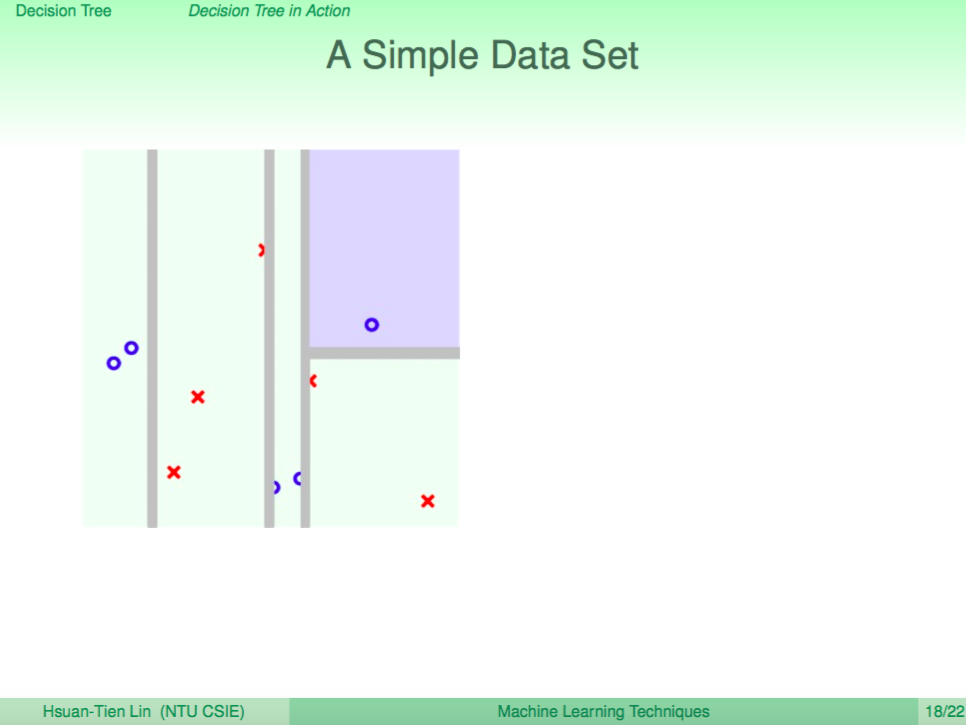
直到不能分了之後,回傳分類的結果(塗上顏色)
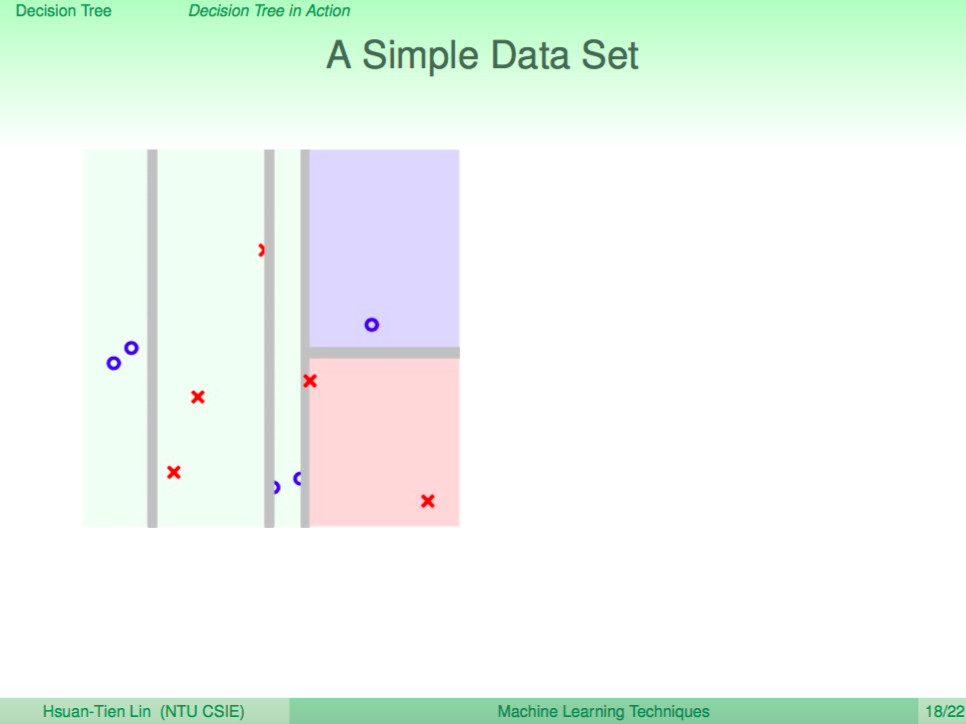
遞迴往上回傳
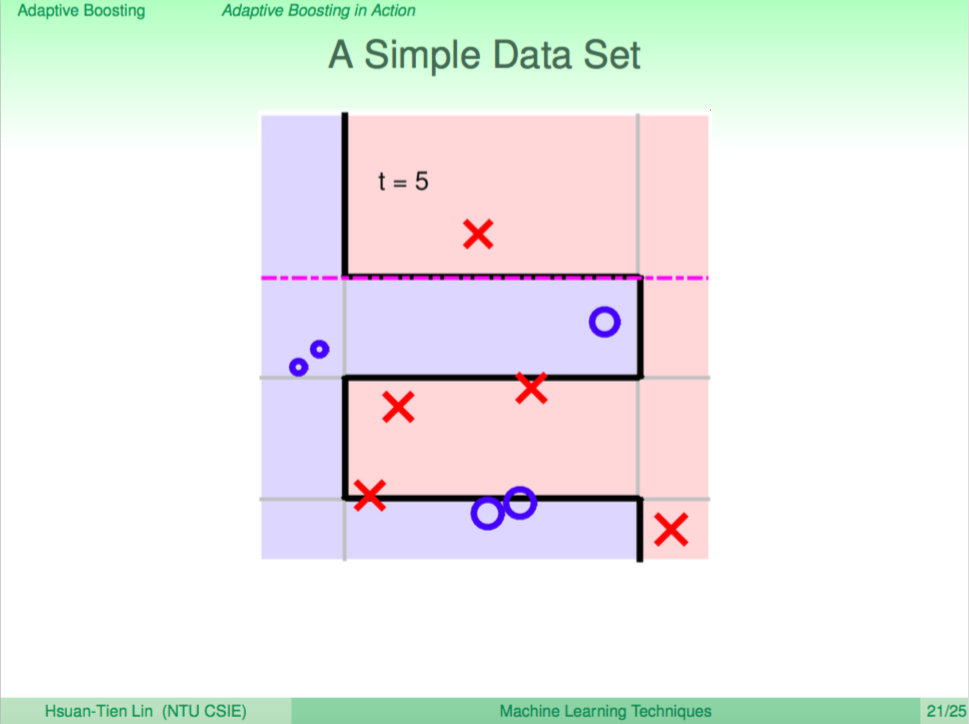
最後分完所有資料
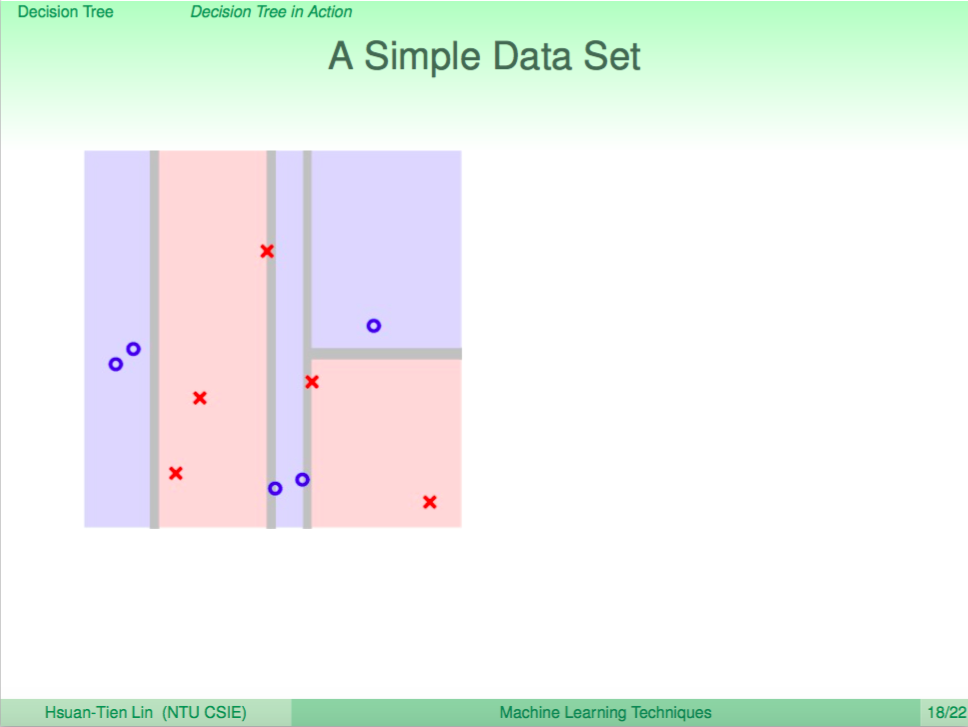
比較 CART 與 AdaBoost 分出來的結果
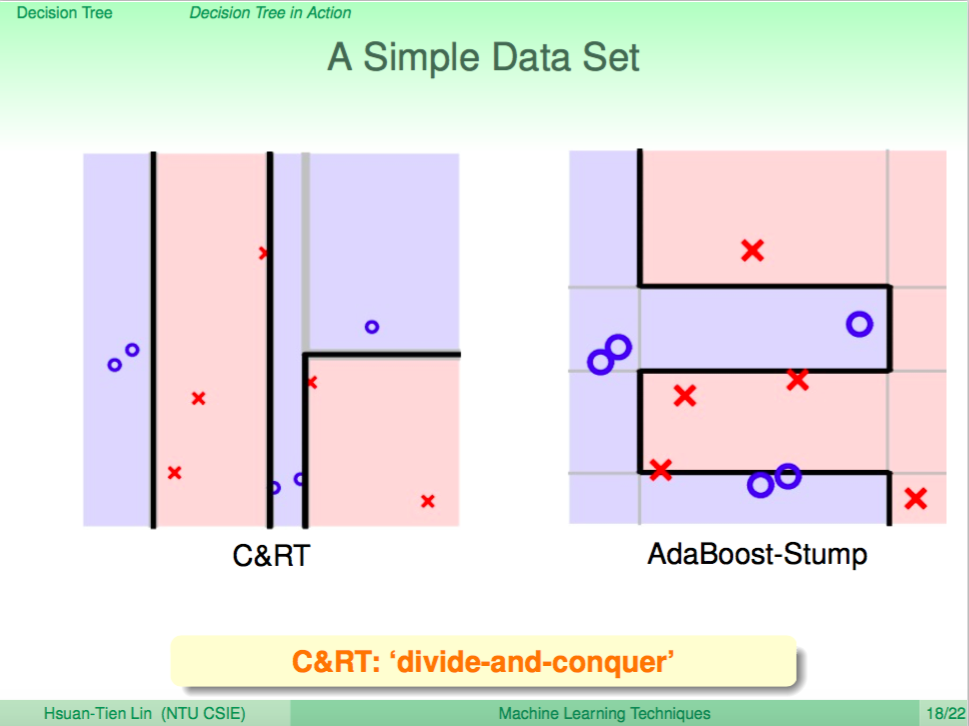
CART 在實務上的優勢
CART 在實務上的優勢如下:1. 比較容易解釋 2. 多元分類也很容易處理,幾乎不用改演算法 3. 枚舉特徵也可以處理 4. 遺失特徵也可以進行預測 5. 相對來說在訓練上很有效率

總結
在介紹了各種 Aggregation 模型之後,我們介紹了第一個 Non-Linear 的 Aggregation 模型 Decision Tree,Decision Tree 其實有各種不同的變形,我們這邊介紹的是一個算是相當有名的 Decision Tree CART,下一講我們將介紹,如果我們要使用 Aggregation Model 的 Aggregation Model,也就是兩層 Aggregation Model,我們要怎麼做呢?