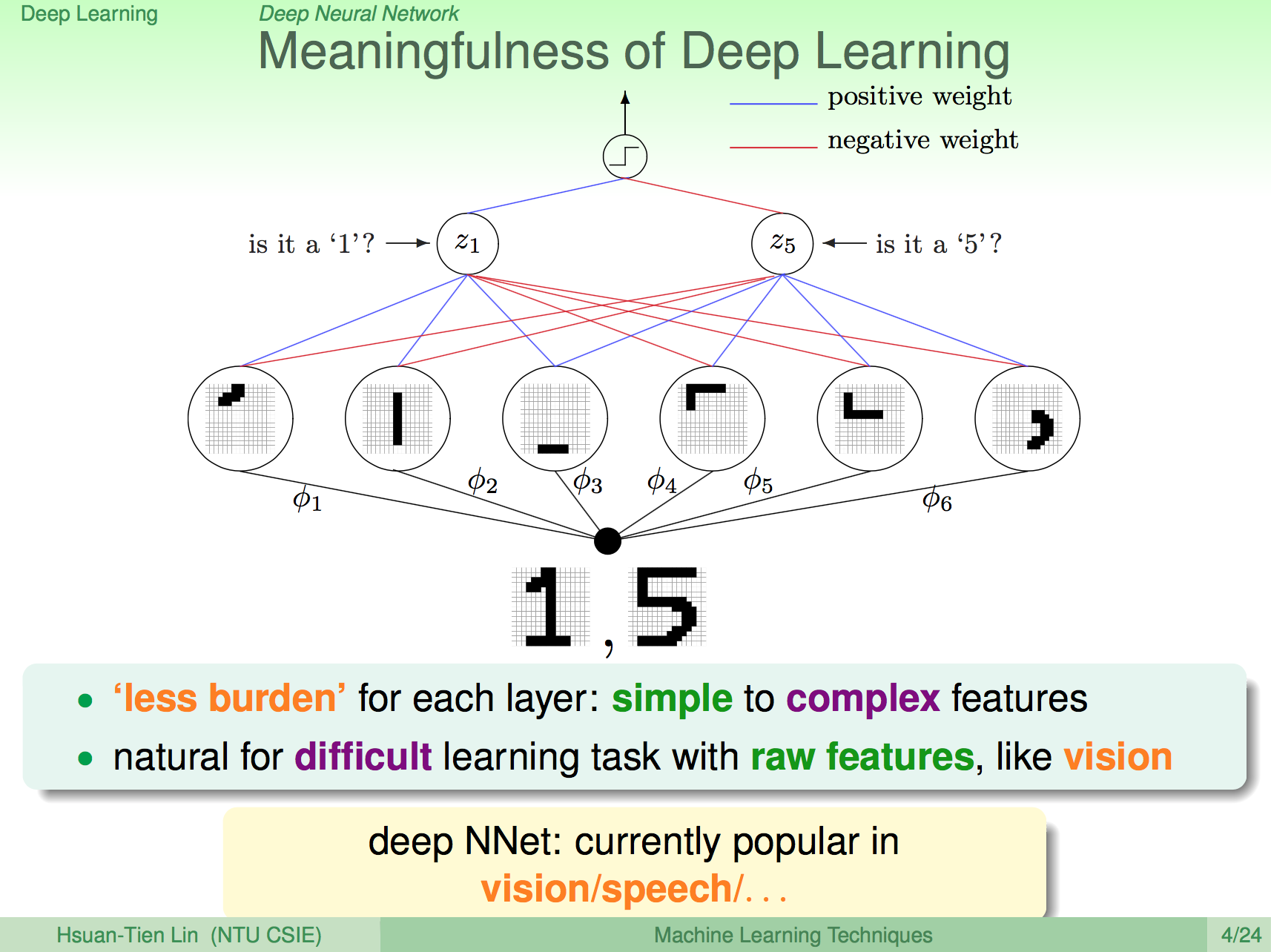
之前看到〈『致敬赵雷』基于TensorFlow让机器生成赵雷曲风的歌词〉這篇文章覺得非常有趣,因此一直都想自己動手試試看,中國有趙雷,那台灣要找什麼值得紀念的音樂人來作這個歌詞機器學習模型呢?我想張雨生應該會是台灣非常值得令人紀念的音樂人之一了。
程式的基礎我使用了之前在 GitHub 上有點小小貢獻的一個 Project 作為程式碼基礎,這個 Project 是 char-rnn-tf,可以用於生成一段中文文本(訓練與料是英文時也可以用於生成英文),訓練語料庫我收集了張雨生的百餘首歌詞(包含由張雨生演唱或作曲的歌詞),由於這樣的歌詞語料還是有些不足,因此也加入了林夕、其他著名歌詞、新詩作為輔助,整個語料庫大致包含 74856 個字、2612 個不重複字(其實語料庫還是不足)。
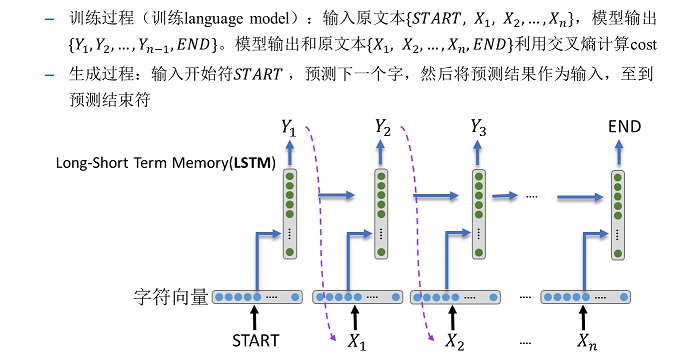
演算法基本上就是 LSTM,細節在此就不多加著墨,若有興趣可以在這篇文章了解一下,沒有時間的人,也可以看看 char-rnn-tf 這個 Project 作者所做的這張圖(見下圖),對概念了解一下。
相關程式碼我放在這邊:Tom-Chang-Deep-Lyrics,如何安裝環境、如何訓練、如何生成歌詞,基本上都寫在 Readme 了,大家可以前往瞧瞧。
歌詞產生結果
範例一:夢想
訓練完模型之後(用 macbook air 大致上需要 1 天的時間),由於大眾對張雨生歌詞的印象應該就是「我的未來不是夢」,因此我首先使用「夢想」作為 seed,結果產生歌詞如下:
夢想會有心
我不願再區福 也不是一種把你一樣偷偷
我的心中有無奈
在我的心裡流 你的身影 你的轉身 你的沈靜 框進畫裡印象派的意
我有個朋友聽我說故舊 這一路悠揚的街長
我是天堂飄輝在天空裡
期待愛人看不同的眼睛
我等待與你身邊
你的歡念 你的灑明 在我心底都是飄逸水墨
我想你 愛過了我的一切
為你一起孤定我的美麗
產生的結果,歌詞機器學習模型先把詞補成句子「夢想會有心」,其實補得蠻好的啊!
「我不願再區福 也不是一種把你一樣偷偷 我的心中有無奈」
這邊雖有錯字,但也不至於不能理解。
「在我的心裡流 你的身影 你的轉身 你的沈靜 框進畫裡印象派的意」
這裡則結合了一首新詩,自創了歌詞。’
「我有個朋友聽我說故舊 這一路悠揚的街長」
這一句歌詞結合了張雨生的歌曲永公街的街長,說明歌詞機器學習模型的確有張雨生的影子,但悠揚的街長感覺怪怪的 XD
範例二:我的未來不是夢
從上一個範例,我們可以了解這個歌詞機器學習模型的效果還算不錯,且看起來比起〈『致敬赵雷』基于TensorFlow让机器生成赵雷曲风的歌词〉這篇所產生的歌詞還要好,仔細看趙雷歌詞產生的結果就會覺得歌詞有點不知所云,而我這邊訓練完的結果,看起來語意會比較明確一些。
接著上個範例,我們來試試看「我的未來不是夢」作為 seed。
我的未來不是夢
我只是真的勇敢
我是一棵秋天的樹 枯少的葉片顯過我
如果有愛能值得這些愁
這個世界保持安靜的距離
熱鬧容易 難得孤寂
我才捨不得問自己
從哪裡來又沒有用 感情和你的歸懷
你是我的姊妹
你是我的 BABY
讓我們的是 BAD BOY 難道我曾經默默縱容 那全是你犯的錯 喔
你贏 我不想與你再爭辯
我說你贏 我再也不想爭辯 請你轉過頭 我有哭泣的尊嚴
我是你的 BABY 我說得再多
「我的未來不是夢 我只是真的勇敢」
如果少了「只」感覺會更好一些。
「我是一棵秋天的樹 枯少的葉片顯過我 如果有愛能值得這些愁」
這邊則是致敬了張雨生的「我是一棵秋天的樹」的歌詞。
「你是我的姊妹」、「讓我們的是 BAD BOY」、「你贏 我不想與你再爭辯」
這邊則結合了「姊妹」「BAD BOY」「你贏」三首歌詞,有些地方說得通,但其實很難讓整首歌詞語意一致,這是目前這個歌詞機器學習模型需要改善的地方。
範例三:永遠不回頭
接下來試試經典歌曲「永遠不回頭」作為 seed。
永遠不回頭
我只能誠實你只能真摰 你無需幻想你無需作夢
當舞台來喝采聲星 為你的心呢的旋律
我是如此的愛 被我無深在心靈
我的愛沒有書香的清澈 我的愛沒有酒醇的狂語
我的愛沒有鑽石的雨 我是真的 人是假的唯
我要你的愛不曾衰竭 只要越來越不知道那無遲
別用你的眼 用我的心
好好一些感動
我在你心裡面看不見
我的世界裡用天地溫柔
永遠的感覺你和你
「永遠不回頭 我只能誠實你只能真摰 你無需幻想你無需作夢」
語意上蠻貼切的。
「別用你的眼 用我的心 好好一些感動」
「我在你心裡面看不見 我的世界裡用天地溫柔 永遠的感覺你和你」
這邊看不出是致敬哪首歌詞,比較像是歌詞機器學習模型自己從看過的語料中創作出來的,在字彙這麼少的情況下能夠這樣創作真的很不容易,想想自己小時候寫作文就知道這有多難,機器等於是一天學會作文。
範例四:我學會飛翔
接下來使用「我學會飛翔」作為 seed,這是範例中唯一由張雨生寫的歌詞,其他範例都是合作過的歌曲(雖然也都放在語料庫中),哎呀,真不會選範例!
我學會飛翔
深空之前如何困見 那裡有愛的人
為誰呼喚我 那一天我依稀回來
我們的愛情是迷霧 我總是深彎
我不能相信 何難自己
當風和日麗 陽春三月天
燦爛的心境 醉人的詩篇
或許紅磚上 或許小湖沿
繽紛的足跡 飛揚的笑靨
純潔的性靈 仿如剛清醒
又似蒙蔽 你的輪廓 在汗水中穿梭的角梗
吐著濃濃的煙霧恣任冥思出星
燦爛的陽光溫暖不到這樣的角落
一想到你呀 就讓我快樂
就好比蜻猴呀穿梭梭林 聚成了身邊
「我們的愛情是迷霧」
這也是歌詞機器學習模型自己創作出來的,覺得蠻厲害的。
「當風和日麗 陽春三月天 燦爛的心境 醉人的詩篇」
這邊的詞有點高水準,所以其實是 Overfitting,抄了張雨生的「三月的天真」這首歌詞。
範例五:沒有菸抽的日子
接下來試試另一首經典歌曲「沒有菸抽的日子」作為 seed。
沒有菸抽的日子 喔
蒼匆的年宴不想留念你的存在
等待那一天鐘
不能說
我不會知道該怎麼做
當秋天葉落 西風來臨後
樹靈的枯枝 曳搖千萬萬 搖積不再有不停 是否不能呼吸
你也能夠 不顧
常常常覺得對自己嗎 難道我真的更好
oh 不醉 就學不會
好男人是不是都躲在家裡
為何身邊六塊肌全對女人沒興趣
有時我真懷疑 纏綿悱惻的劇情
幸福結局 只出現在日劇
女人的心 好比 放大鏡
「沒有菸抽的日子 喔」
「oh 不醉 就學不會」
這兩句真的喔的很貼切啊!很可惜後面 Overfitting 了~
範例六:漂向北方
最後我們來試試不是張雨生的歌曲看看,刻意選了近期還蠻紅的歌曲「漂向北方」作為 seed。
漂向北方 別問我家鄉
直到昏景 等到癡邊
我期待 在我的窗中
你給我一個感覺
肯定的愛情
擁有工作我的愛 請我的愛沒有書醇的狂向
直到傻風上煙中深起
你知道我不會猜你
我的笑容隨著煦煦和風 溫暖吹襲一股月色迷濛
我的歌聲衝出節節喉嚨 騷動八方就該天地星座 快同我怒吼
大度能寬容 滄海樂悠悠 誰又不想放下身段快意自由
失意也會有 得意也會有 反正都是生不帶來死不帶走
「漂向北方 別問我家鄉 直到昏景 等到癡邊」
補完的詞還不錯,「等到癡邊」比較不能理解,但算是有趣的創作吧。
「我期待 在我的窗中 你給我一個感覺 肯定的愛情」
致敬了我期待,感覺真的有在期待的感覺。
後面好像 Overfitting 了張雨生的「門外還有愛」,但整首詞的語意還算一致,算是一個不錯的結果。
以上就是這個「基於 LSTM 深度學習方法研發而成的張雨生歌詞產生模型」的實驗結果,產生的詞算是可讀,而且有些還蠻有意思的,比較大的問題是上下文的語意可能會不一致,這樣的問題目前也有很多論文在解了,大體上就是用多層的 LSTM,可以將句子為 level 做 Encode 之後做一層 LSTM,將段落為 level 做 Encode 之後做一層 LSTM,結合原本的字詞 level 的 LSTM 模型,應該就可以做出上下文語意一致的歌詞產生模型了,如果大家有做出來,別忘了分享一下啊!