
林軒田教授機器學習技法 Machine Learning Techniques 第 14 講學習筆記
前言
本系列部落格文章將分享我在 Coursera 上台灣大學林軒田教授所教授的機器學習技法(Machine Learning Techniques)課程整理成的心得,並對照林教授的投影片作說明。若還沒有閱讀過 第 13 講 的碼農們,我建議可以先回頭去讀一下再回來喔!
範例原始碼:FukuML - 簡單易用的機器學習套件
我在分享機器學習基石課程時,也跟著把每個介紹過的機器學習演算法都實作了一遍,原始碼都放在 GitHub 上了,所以大家可以去參考看看每個演算法的實作細節,看完原始碼會對課程中的數學式更容易理解。
如果大家對實作沒有興趣,只想知道怎麼使用機器學習演算法,那 FukuML 絕對會比起其他機器學習套件簡單易用,且方法及變數都會跟林軒田教授的課程類似,有看過課程的話,說不定連文件都不用看就會使用 FukuML 了。不過我還是有寫 Tutorial 啦,之後會不定期更新,讓大家可以容易上手比較重要!
熱身回顧一下
上一講介紹了深度學習神經網路,基本上神經網路林軒田老師只說明了兩講,這一講將進入一個新的 Machine Learning 演算法 Radial Basis Function Network(我個人不太覺得這個是神經網路演算法),並延伸介紹了其中會使用到的 K-means 分群演算法。

回顧一下 Gaussian SVM
Gaussian Kernel 也稱為是 Radial Basis Function(RBF),定義一種距離關係,Gaussiam SVM 也就是使用這些 RBF 經過線性組合的預測模型。

RBF Network 的定義
RBF Network 定義是資料點與代表性中心點投票出來的結果作為預測,其中每個中心點具有代表性,資料點經過 RBF 距離公式的轉換之後(距離越小,越有影響力),再經過 beta 投票。
而 RBF Network 要學習的參數就是中心點 u 以及每個中心點距離公式的權重 beta。
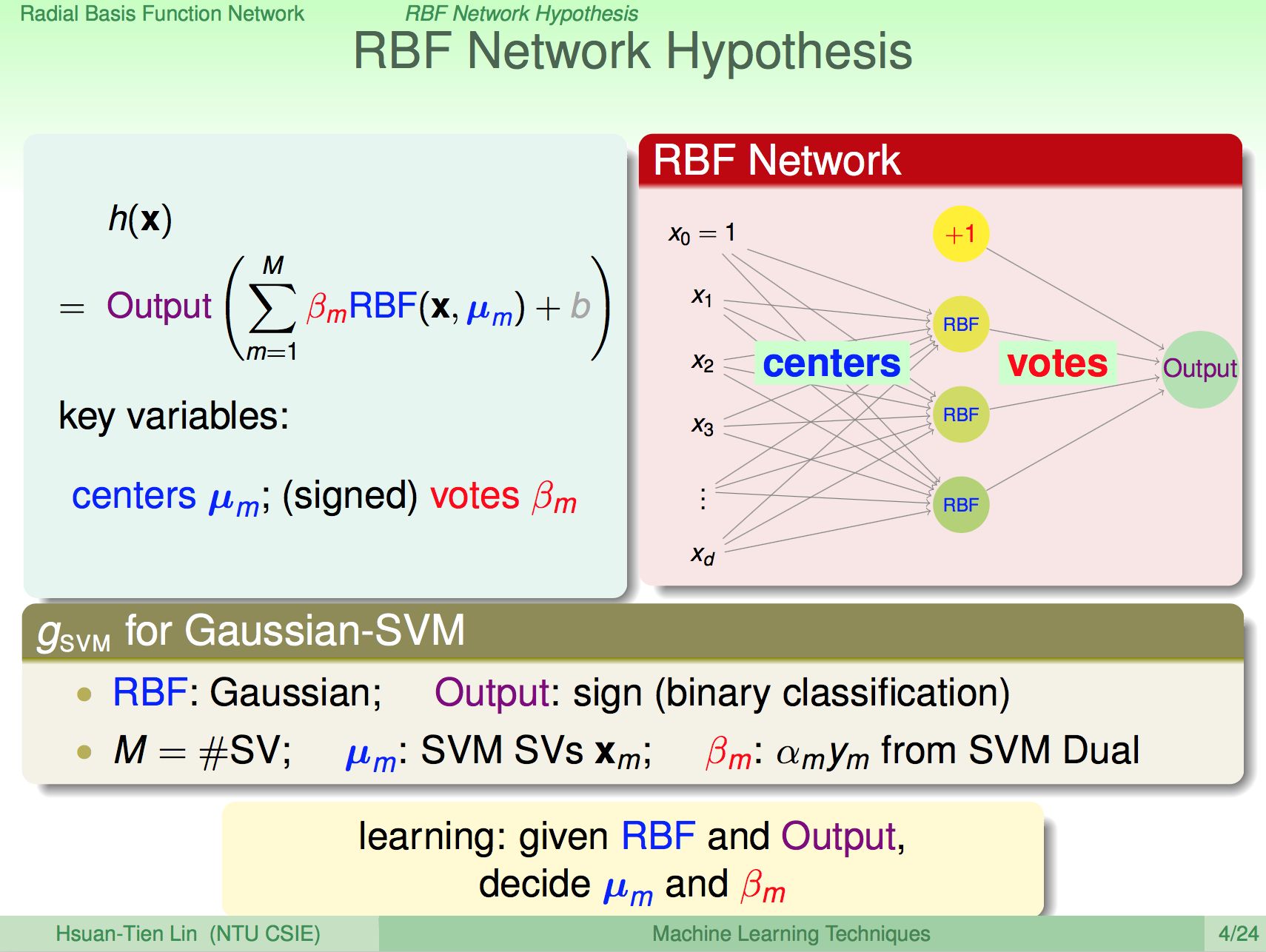
Full RBF Network
了解定義之後,我們就要求出 RBF Network 最佳化的 u 及 beta,一種情況我們是將所有的資料點都當成是重要的中心點,這種情況,然後 beta 直接用 y 當成加權,這樣就是所謂的 Full RBF Network,這樣的預測模型就完全沒有訓練過程,只要將所有的點記下來,然後用 RBF 距離公式計算投票來定義新的資料點應該是屬於什麼。

Nearest Neighbor
由於每次預測都要使用所有的訓練資料點來計算預測結果很費力,我們從距離公式可以了解,投票結果大部分會受最近距離的中心點影響,所以我們其實可以只看最近一點中心點的 RBF 投票結果就好,這就是所謂的 Nearest Neighbor,如果是看最近 k 點中心點的 RBF 投票結果就是所謂的 K Nearest Neighbor。

Beta 不使用相同權重
Full RBF Network 的 Beta 使用相同權重其實就是 Nearest Neighbor,現在我們不想要讓 Beta 使用相同權重,因此要透過訓練資料來計算出最佳的 Beta 權重,最佳的 Beta 有公式解,且這個結果會讓 RBF Network 得到 Ein=0,這樣其實會有 overfitting。

使用更少的中心點來正規劃
我們從 SVM 中看到 SVM 其實只考慮了幾個點(SV)來決定胖胖的線,那 RBF Netwrok 應該也可以用同樣的概念來找出幾的重要的中心點,然後再來計算出最佳的 beta 就好,這樣就可以避免 overfitting。

中心點如何決定?
中心點如何決定並不是一個簡單的問題,我們必須要找出讓訓練資料跟各中心點距離最小,然後又要找出訓練資料最佳的分組結果,這是無法找出最佳化公式的問題。

分別最佳化(1)
其中一個方法就是做最佳化,首先假設我們已經決定了最佳的中心點,那要算出資料點應該要分在哪個中心點的分組就非常容易,就看跟哪個中心點距離最小就可以了。

分別最佳化(2)
假設現在分組已經決定了,找出最佳化的中心點也很容易,將距離公式進行微分資料就可以知道最佳的中心點就是分組所有資料點的平均。

K-Means 算法
經過以上的推導,我們可以知道 K-Means 演算法如下:
- 先隨意從資料點找出 k 個資料點當成是初始的中心點
- 計算資料點的分組
- 資料分完組之後,計算各組資料點的平均當成是新的中心點
- 重複 2 跟 3 直到中心點不再改變

RBF Network 搭配 K-means 中心點
現在我們將 RBF Netwrok 搭配 K-means 算出的中心點來做出先的 RBF Network 模型:
- 使用 K-means 計算出 k 個最重要的中心點(k 要設幾個要自己試,可以用 cross-validation)
- 將訓練資料 x 經過 k 個 RBF 距離公式進行特徵轉換
- 將特徵轉換後的訓練資料跑 linear model 計算最佳化的 beta
- 如此就得到了訓練完後具有正規化性質 RBF Network 了

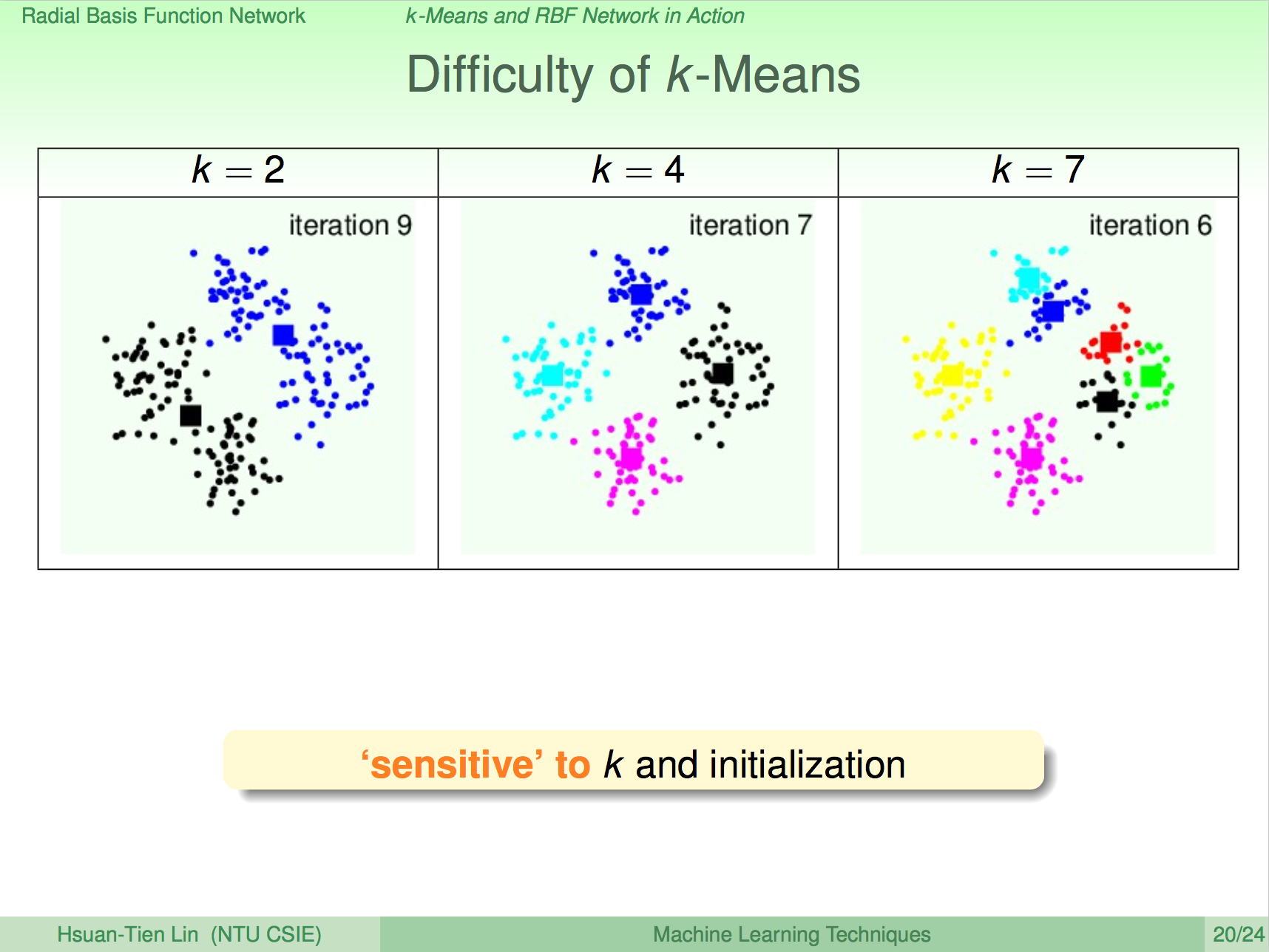
K-means 的問題
K 很難決定、初始化的中心點也會影響分群的結果,這是目前無解的,我們只能透過 cross validation 來決定最好的 k 是幾個,而初始化的中心點只能多試只次來避面模型是落在局部最佳化。
總結
這一章介紹了 RBF Network,基本上就是透過距離公式及中心點來對資料點進行投票的一個算法,而中心點就是一種代表性,為了決定中心點,我們可以使用 K-means,了解 RBF Network 的核心概念之後,覺得 RBF 算是蠻簡單的,幾乎不太需要訓練,相對的,我也覺得 RBF Network 的用處比較沒那麼大。


