
林軒田教授機器學習技法 Machine Learning Techniques 第 8 講學習筆記
前言
本系列部落格文章將分享我在 Coursera 上台灣大學林軒田教授所教授的機器學習技法(Machine Learning Techniques)課程整理成的心得,並對照林教授的投影片作說明。若還沒有閱讀過 第 7 講 的碼農們,我建議可以先回頭去讀一下再回來喔!
範例原始碼:FukuML - 簡單易用的機器學習套件
我在分享機器學習基石課程時,也跟著把每個介紹過的機器學習演算法都實作了一遍,原始碼都放在 GitHub 上了,所以大家可以去參考看看每個演算法的實作細節,看完原始碼會對課程中的數學式更容易理解。
如果大家對實作沒有興趣,只想知道怎麼使用機器學習演算法,那 FukuML 絕對會比起其他機器學習套件簡單易用,且方法及變數都會跟林軒田教授的課程類似,有看過課程的話,說不定連文件都不用看就會使用 FukuML 了。不過我還是有寫 Tutorial 啦,之後會不定期更新,讓大家可以容易上手比較重要!
熱身回顧一下
上一講我們介紹了如何使用 Blending 及 Bagging 的技巧來做到 Aggregation Model,可以使用 Uniform 及 Linear 的方式融合不同的 Model。至於以 Non-linear 的方式融合 Model 就需要依據想展現的特性去調整演算法來做到,這一講將介紹 Adaptive Boosting 這種特別的演算法。
幼稚園學生學認識蘋果的故事(一)
我們用一個幼稚園學生在課堂上學認識蘋果的故事來作為開頭說明,在課堂上老師問 Michael 說「上面的圖片哪些是蘋果呢?」,Michael 回答「蘋果是圓的」,的確蘋果很多是圓的,但是有些水果是圓的但不是蘋果,有些蘋果也不一定是圓的,因此 Michael 的回答在藍色的這些圖片犯了錯誤。
幼稚園學生學認識蘋果的故事(二)
於是老師為了讓學生可以更精確地回答,將 Michael 犯錯的圖片放大了,答對的圖片則縮小了,讓學生的可針對這些錯誤再修正答案。於是 Tina 回答「蘋果是紅的」,這的確是一個很好的觀察,但一樣在底下藍色標示的這是個圖片犯了錯,番茄跟草莓也是紅的、青蘋果的話就是綠的。

幼稚園學生學認識蘋果的故事(三)
於是老師又將 Tina 犯錯的圖片放大了,答對的圖片縮小,讓學生繼續精確的回覆蘋果的特徵。

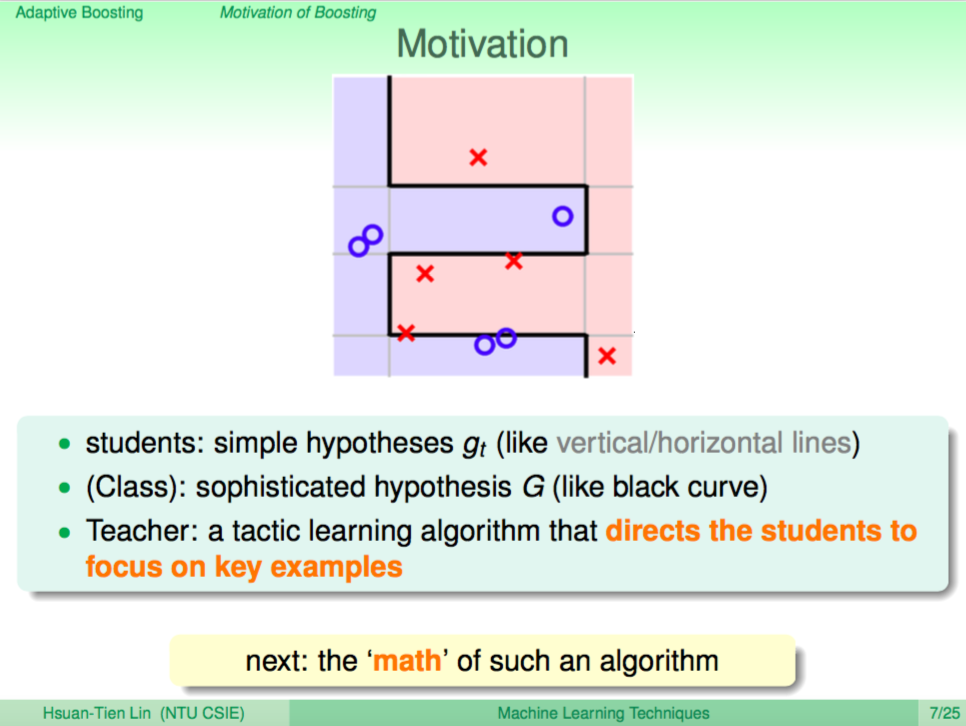
動機
這樣的教學過程也是一種可以用來教機器如何學習的過程,每個學生都只會一些簡單的假設 gt(蘋果是紅的),綜合所有學生的假設就可以好好地認識出蘋果的特徵形成 G,而老師則像是一個演算法一樣指導學生方向,讓錯誤越來越少。
接下來我們就要介紹如何用演算法來模擬這樣的學習過程。
有權重的 Ein
老師調整圖片放大縮小的教學方式,在數學上我們可以為每個點犯錯時加上一個權重來表示。

每一回合調整權重
那我們如何調整權重呢?我們每次調整權重,是希望每個學生能學出不一樣的觀點,這樣才能配合所有學生的觀點做出對蘋果完整的認識,因此挑整權重時應該要讓第一個學習到的 gt 在 u(t+1) 時這樣的權重下表現很差。
所謂的表現差就是表現跟丟銅板沒兩樣,也就是猜錯的情況為 1/2。(全猜錯其實算是一個好的表現)
我們讓演算法根據新的權重 u(t+1)(會使 gt 表現很差)再去學習出新的 g(t+1),這個 g(t+1) 就是一個觀點與 gt 不同,但表現卻也不錯的新假設了。

調整權重的數學式
調整權重的數學式如下,我們想讓 gt 在 u(t+1) 的情況下猜對跟猜錯的情況為 1/2,那其實就是將原本的 ut 在猜對時乘上錯誤率(incorrect rate),在猜錯時乘上答對率(correct rate),這樣 gt 在 u(t+1) 的 Ein 就會是 1⁄2 了。

縮放因數
演算法的作者在上述的概念上選擇了一個特別的縮放因數,但基本上就是剛剛上述所說的概念,這個縮放因數我們用 方塊t 來表示(如下圖),這在物理意義上有特別的意義,當 錯誤率 <= 1⁄2 時,縮放因數 方塊t 才會 >= 1,然後在計算下一輪的 ut 時,答錯的點會乘上 方塊t,答對的點會除上 方塊t,這就像老師在小朋友答錯的圖片放大、答對的圖片縮小那樣的教學過程。

初步的演算法
初步的演算法如下,首先第一輪的 u 對每個點都是相同的權重,這時我們學出第一個假設 gt,接下來使用 方塊t 調整權重得出 u(t+1),然後繼續學出第二個假設 g(t+1),我們可以繼續這樣的過程學出更多假設,現在只剩下一個問題,如何融合所有的假設呢?
我們可以用之前學過的 blending 使用 uniform 或是 linear 來融合,但這邊作者選擇了一個特別的演算法在計算過程中融合所有的假設。

演算過程中就算出融合假設的權重
這邊作者想了一個方法可以在演算過程中就算出融合假設的權重,這邊權重 alpha t = ln(方塊t),這在物理意義上也有特別的意義。當錯誤率是 1⁄2 跟丟銅板沒兩樣時,那 方塊t 會等於 1,這時 ln(方塊t) 就會是 0,代表這個假設的權重是 0,一點用都沒有。當錯誤率是 0 的時候,那 方塊t 會等於無限大,這時 ln(方塊t) 就會是無限大,我們可以只看這個超強的假設 gt 就好。
綜合以上,這個演算法就是 Adptive Boosting。我們有 weak learning 就上課堂上的幼稚園學生;我們有一個演算法調整權重就像老師會調整圖片大小引領學生學習;我們有一個融合假設的方法就像我們將課堂上所有學生的觀點融合起來一樣。

Adaptive Boosting(AdaBoost) 演算法
詳細 Adaptive Boosting 演算法如下所示,中文又稱這個演算法就皮匠法。

理論上的保證
跟去理論上的保證只要 weak learner 比亂猜還好,那 AdaBoost 可以很容易地將 Ein 降到 0,而 dvc 的成長也相對慢,因此當資料量夠多時,Eout 理論保證會很小。

Weak Learner:Decision Stump
AdaBoost 使用的 Weak Learner 是 Decision Stump,是一個只能在平面上切一條水平線或垂直線的 Weak Learner,詳細演算法如下,每個假設就是要學習出是一條水平線或垂直線(direction s),切在哪個 feature(feature i),切在那個值(threshold theta)。如果想要看程式碼可以參考:https://github.com/fukuball/fuku-ml/blob/master/FukuML/DecisionStump.py

我們用一個簡單的例子說明 AdaBoost
我們用一個簡單的例子來說明 AdaBoost 的演算過程。
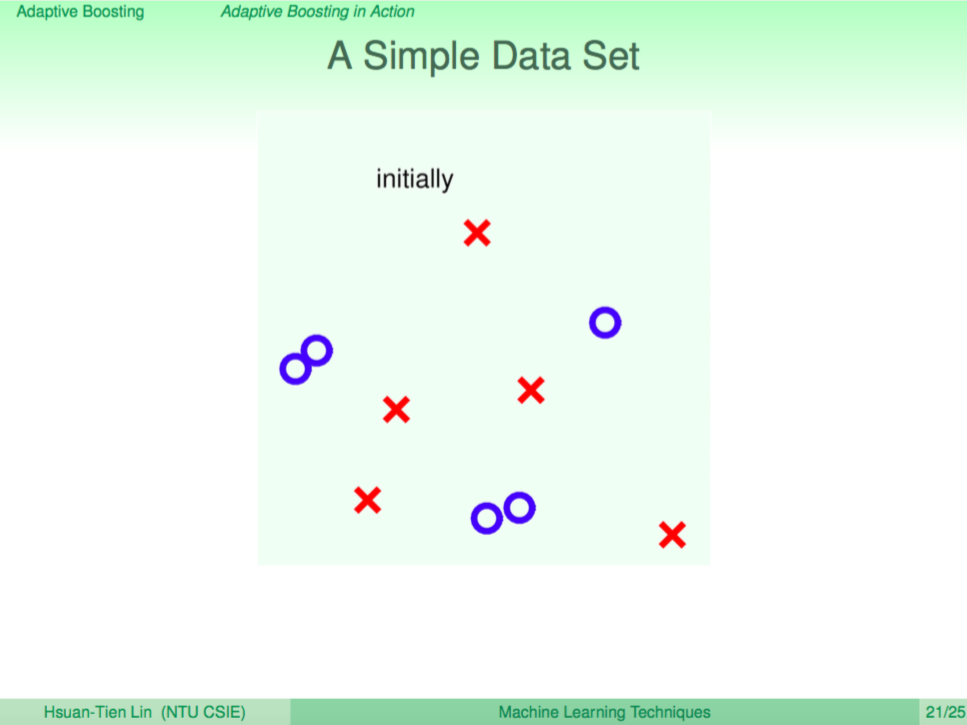
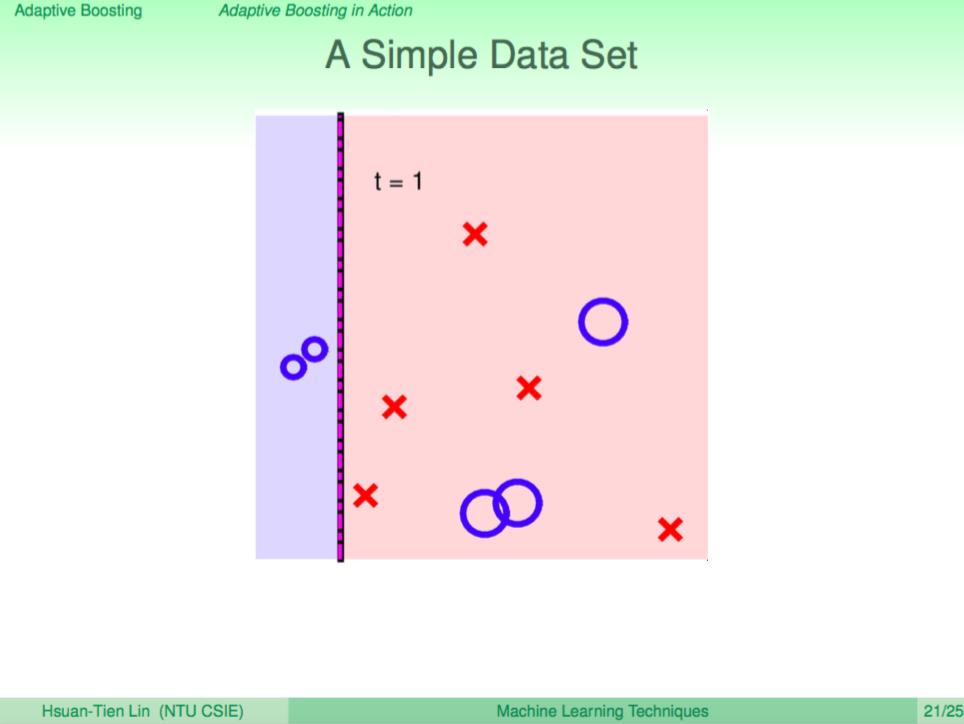
第一輪
第一輪先學出一個 weak learner 切了一個垂直線,這時犯錯的點會放大、答對的點縮小。
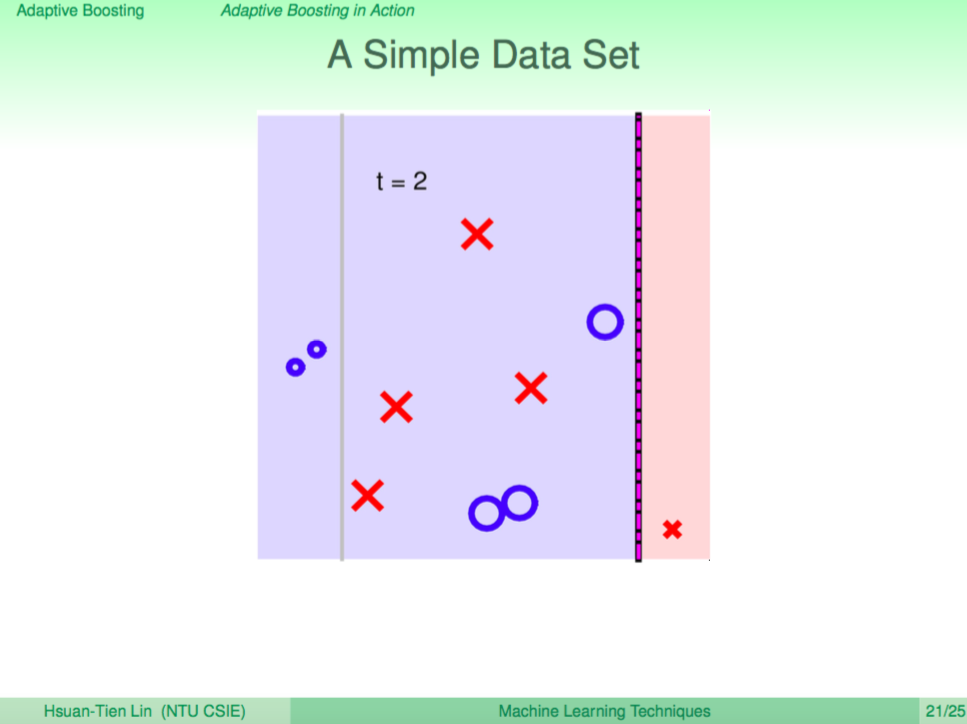
第二輪
根據犯錯放大的權重,再去學出一個不同觀點的 weak learner 再切了一條垂直線,根據答案再對點的權重調整。
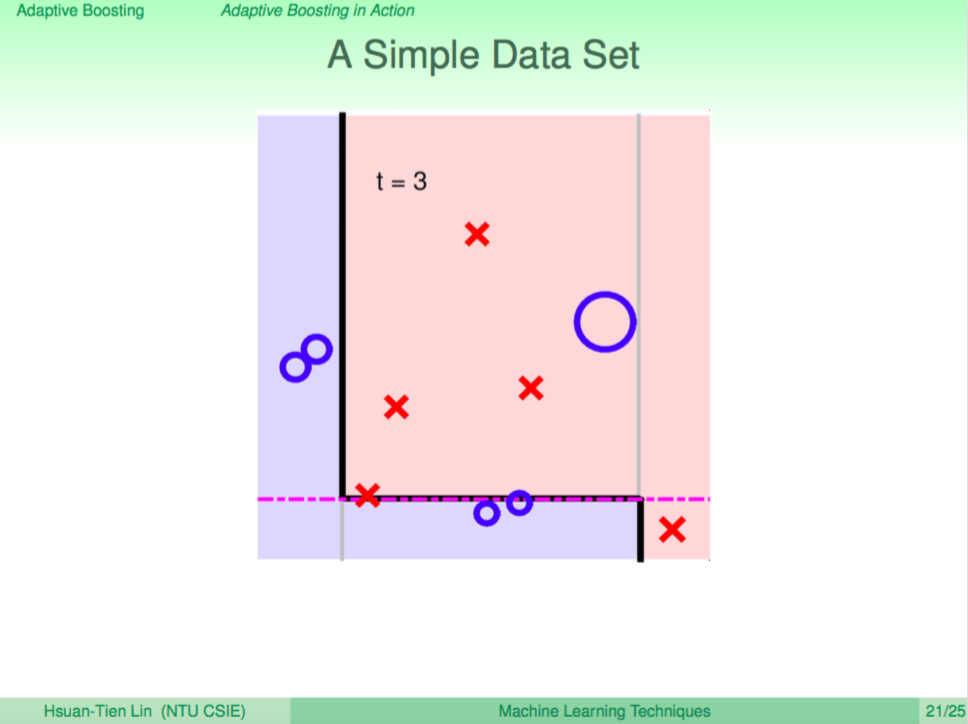
第三輪
第三輪又學出了一個不同觀點的 weak learner 切了一條水平線,現在已經可以看出分界線慢慢變得複雜了。
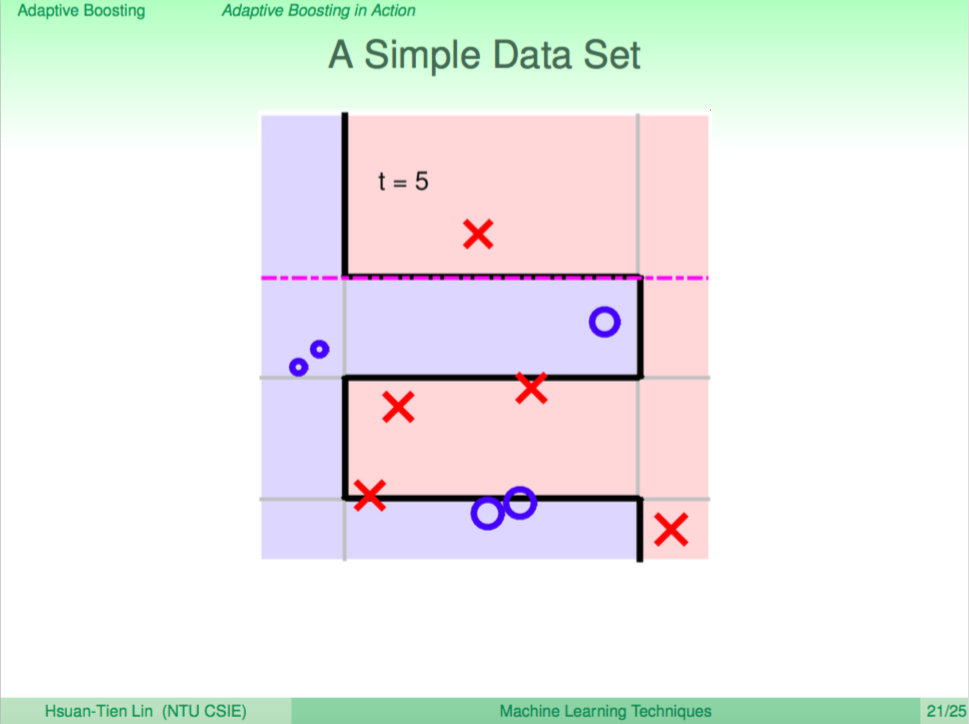
第五輪
持續這樣的過程,AdaBoost 不斷地得出不同的 weak learner,綜合 weak learner 的答案便可以回答一些較複雜的問題。
總結
這一講介紹了 AdaBoost 這個特殊的機器學習演算法,能夠將表現只比丟銅板好一些的 Weak Learner 融合起來去得到更好的學習效果,算是從 Blending 技巧中衍伸出來的一個特殊演算法。


