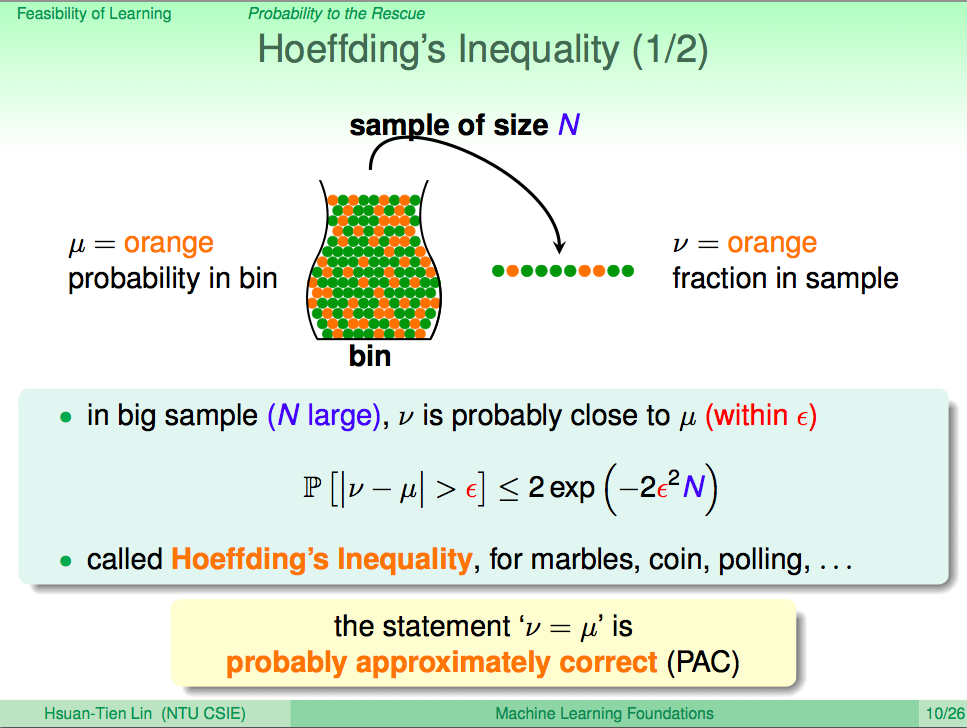
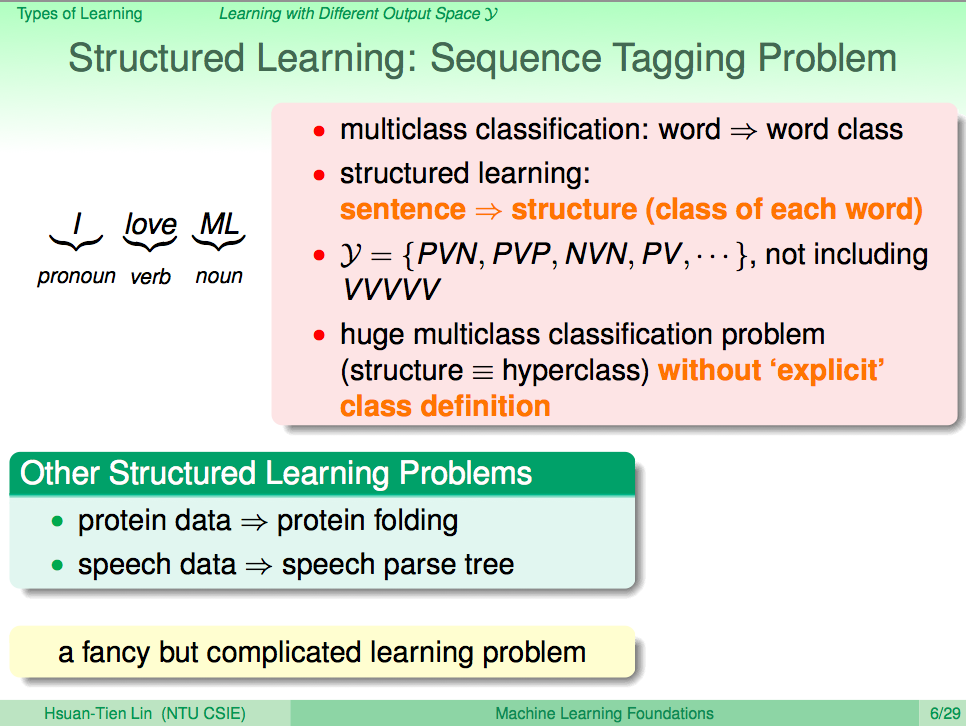
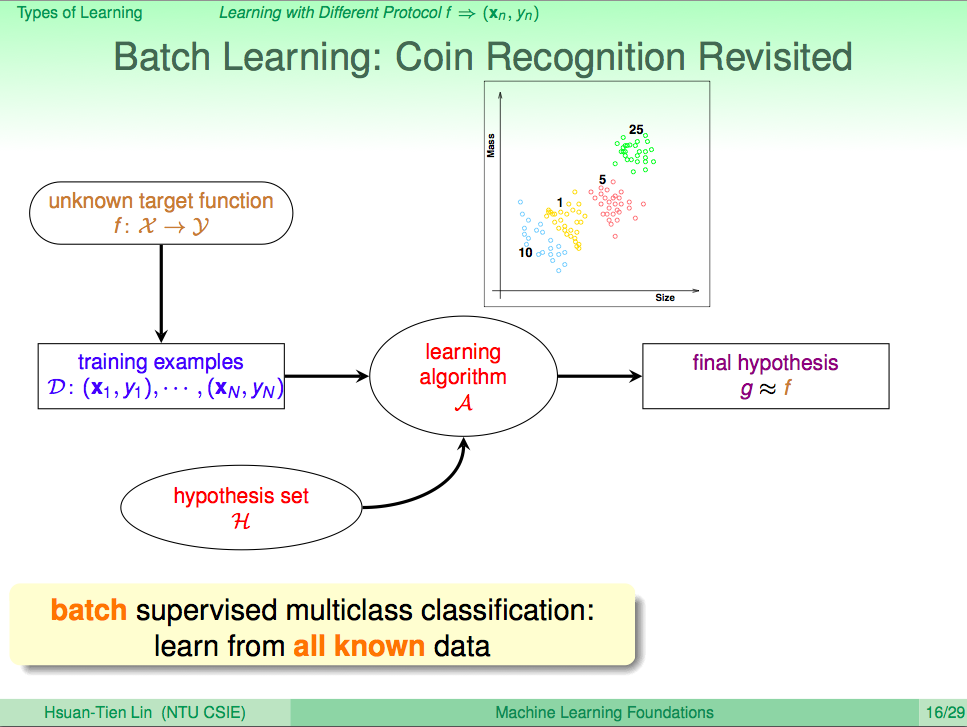
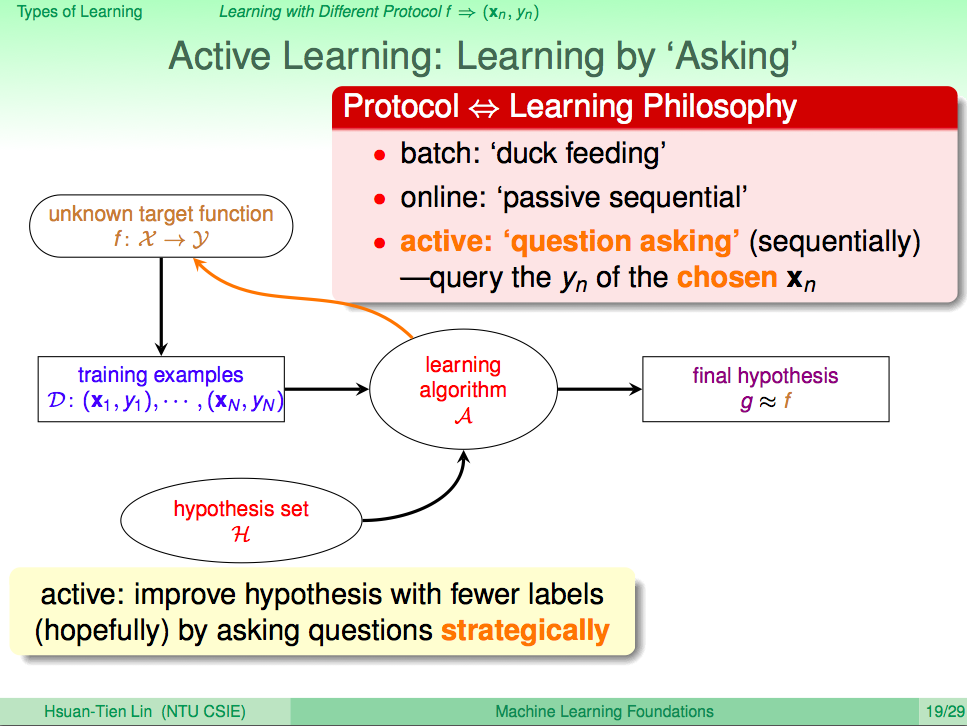
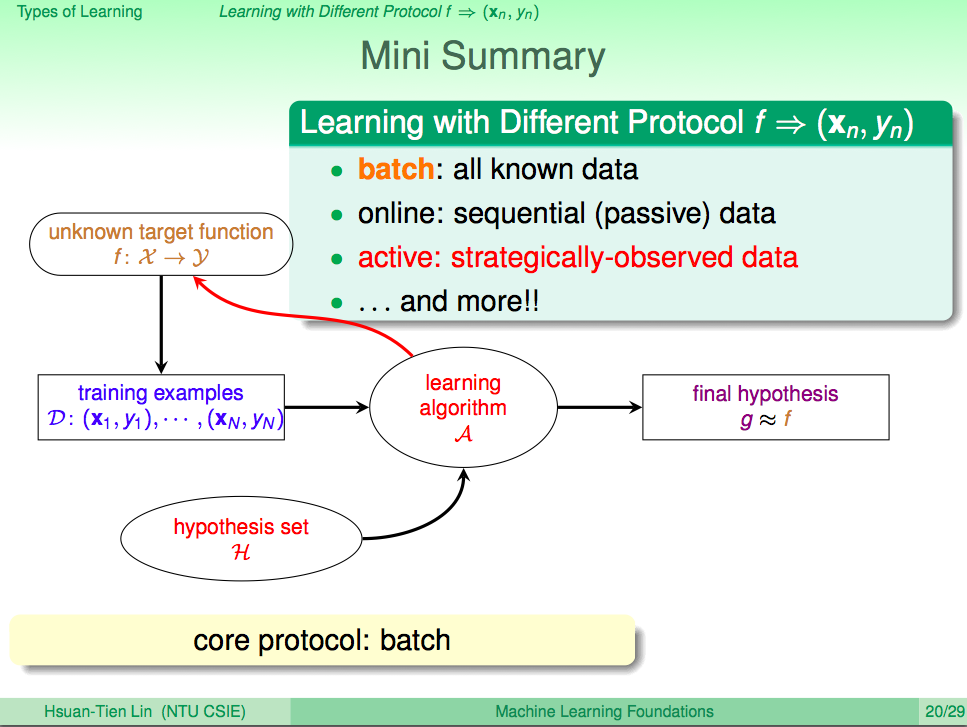
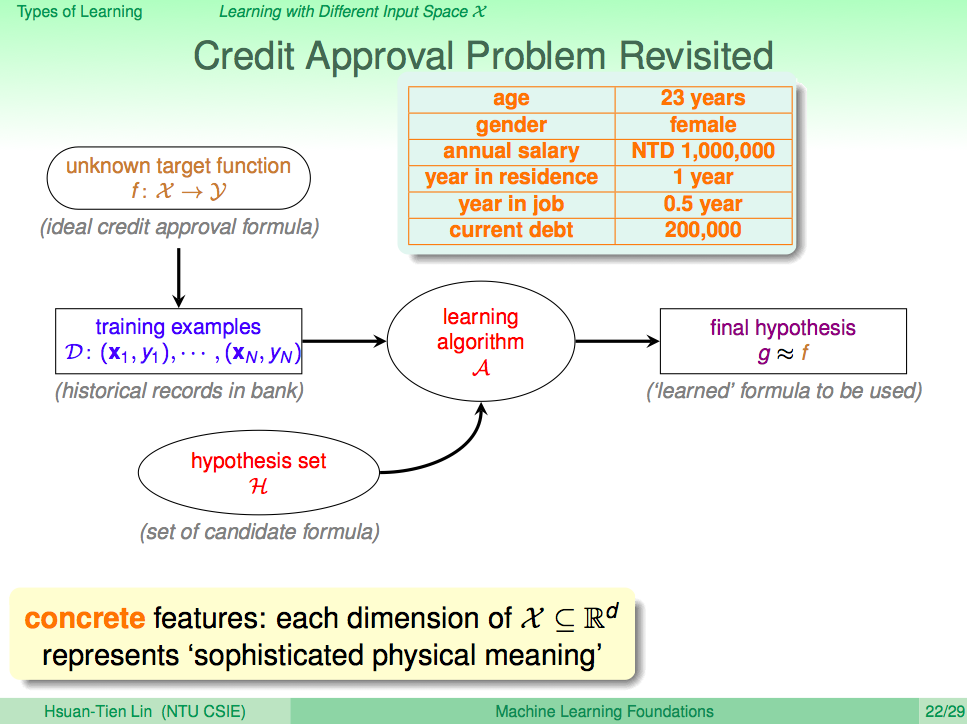
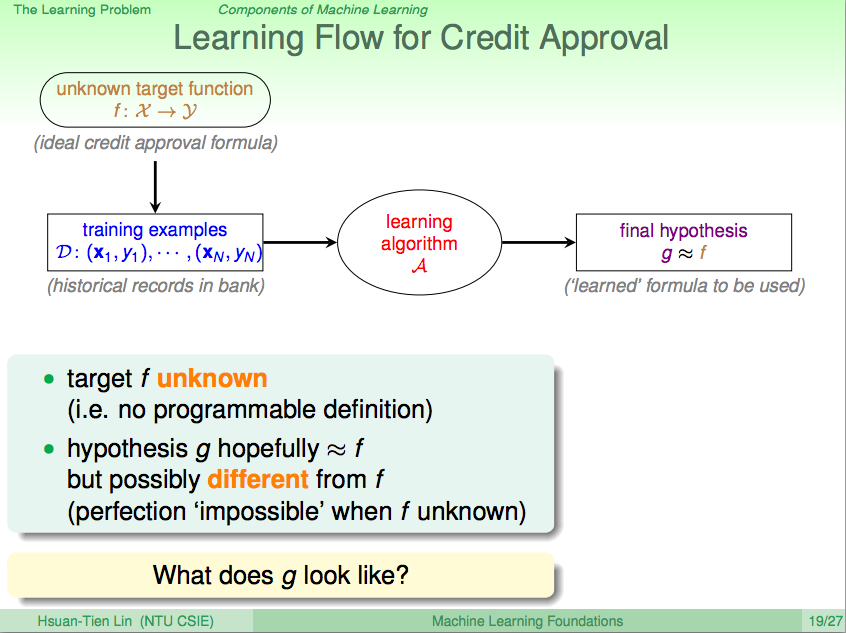
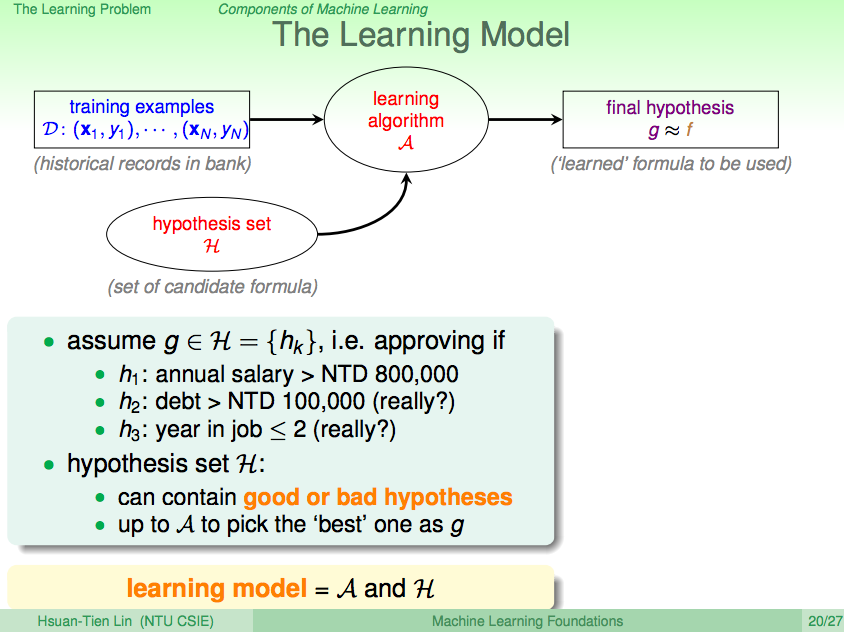
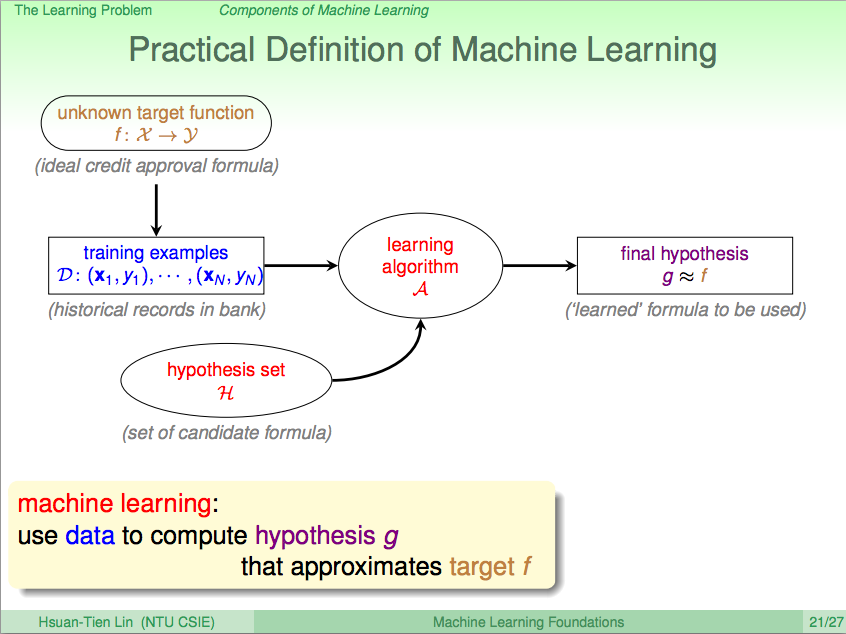
前言
自然語言處理的其中一個重要環節就是中文斷詞的處理,比起英文斷詞,中文斷詞在先天上就比較難處理,比如電腦要怎麼知道「全台大停電」要斷詞成「全台 / 大 / 停電」呢?如果是英文「Power outage all over Taiwan」,就可以直接用空白斷成「Power / outage / all / over / Taiwan」,可見中文斷詞真的是一個大問題啊~
這樣的問題其實已經有很多解法,比如中研院也有提供「中文斷詞系統」,但就是很難用,不僅 API Call 的次數有限制,還很難串,Server 也常常掛掉,真不曉得為何中研院不將核心開源出來,讓大家可以一起來改善這種現象,總之我要棄中研院的斷詞系統而去了。
近來玩了一下 jieba 結巴這個 Python Based 的開源中文斷詞程式,感覺大好,順手發了一些 pull request,今天早上就成為 contributor 了! 感覺真爽!每次發 pull request 總是有種莫名的爽感,既期待被 merge 又怕被 reject,就跟告白的感覺類似啊~
這麼好用的開源中文斷詞系統,當然要介紹給大家用啊!
背後演算法
jieba 中文斷詞所使用的演算法是基於 Trie Tree 結構去生成句子中中文字所有可能成詞的情況,然後使用動態規劃(Dynamic programming)算法來找出最大機率的路徑,這個路徑就是基於詞頻的最大斷詞結果。對於辨識新詞(字典詞庫中不存在的詞)則使用了 HMM 模型(Hidden Markov Model)及 Viterbi 算法來辨識出來。基本上這樣就可以完成具有斷詞功能的程式了,或許我之後可以找個時間寫幾篇部落格來介紹這幾個演算法。
如何安裝
推薦用 pip 安裝 jieba 套件,或者使用 Virtualenv 安裝(未來可能會介紹如何使用 Virtualevn,這樣就可以同時在一台機器上跑不同的 Python 環境):
pip install jieba
基本斷詞用法,使用預設詞庫
Sample Code:
jieba-default-mode.py
#encoding=utf-8
import jieba
sentence = "獨立音樂需要大家一起來推廣,歡迎加入我們的行列!"
print "Input:", sentence
words = jieba.cut(sentence, cut_all=False)
print "Output 精確模式 Full Mode:"
for word in words:
print word
sentence = "独立音乐需要大家一起来推广,欢迎加入我们的行列!"
print "Input:", sentence
words = jieba.cut(sentence, cut_all=False)
print "Output 精確模式 Full Mode:"
for word in words:
print word
得到的斷詞結果會是:
獨立 / 音樂 / 需要 / 大家 / 一起 / 來 / 推廣 / , / 歡迎 / 加入 / 我們 / 的 / 行列
独立 / 音乐 / 需要 / 大家 / 一 / 起来 / 推广 / , / 欢迎 / 加入 / 我们 / 的 / 行列
據原作者的說法,使用預設詞庫的話,繁體中文的斷詞結果應該會比較差,畢竟原來的詞庫是簡體中文,但在這個例子中,我感覺是繁體中文的斷詞結果比較好,這應該只是特例,我們接下來試試看中文歌詞的斷詞結果如何。
中文歌詞斷詞,使用預設詞庫
現在我們使用 回聲樂團 - 座右銘 的歌詞作為中文斷詞測試範例,歌詞我們先做成一個純文字檔,內容如下:
lyric.txt
我沒有心
我沒有真實的自我
我只有消瘦的臉孔
所謂軟弱
所謂的順從一向是我
的座右銘
而我
沒有那海洋的寬闊
我只要熱情的撫摸
所謂空洞
所謂不安全感是我
的墓誌銘
而你
是否和我一般怯懦
是否和我一般矯作
和我一般囉唆
而你
是否和我一般退縮
是否和我一般肌迫
一般地困惑
我沒有力
我沒有滿腔的熱火
我只有滿肚的如果
所謂勇氣
所謂的認同感是我
隨便說說
而你
是否和我一般怯懦
是否和我一般矯作
是否對你來說
只是一場遊戲
雖然沒有把握
而你
是否和我一般退縮
是否和我一般肌迫
是否對你來說
只是逼不得已
雖然沒有藉口
Sample Code:
jieba_cut_lyric.py
#encoding=utf-8
import jieba
content = open('lyric.txt', 'rb').read()
print "Input:", content
words = jieba.cut(content, cut_all=False)
print "Output 精確模式 Full Mode:"
for word in words:
print word
得到的斷詞結果會是:
我 / 沒 / 有心 / 我 / 沒 / 有 / 真實 / 的 / 自我 / 我 / 只有 / 消瘦 / 的 / 臉孔 / 所謂 / 軟弱 / 所謂 / 的 / 順 / 從 / 一向 / 是 / 我 / 的 / 座 / 右銘 / 而 / 我 / 沒有 / 那 / 海洋 / 的 / 寬闊 / 我 / 只要 / 熱情 / 的 / 撫 / 摸 / 所謂 / 空洞 / / 所謂 / 不安全感 / 是 / 我 / 的 / 墓誌 / 銘 / 而 / 你 / 是否 / 和 / 我 / 一般 / 怯懦 / 是否 / 和 / 我 / 一般 / 矯作 / 和 / 我 / 一般 / 囉 / 唆 / 而 / 你 / 是否 / 和 / 我 / 一般 / 退縮 / 是否 / 和 / 我 / 一般 / 肌迫 / 一般 / 地 / 困惑 / 我 / 沒 / 有力 / 我 / 沒 / 有 / 滿腔 / 的 / 熱火 / 我 / 只有 / 滿肚 / 的 / 如果 / 所謂 / 勇氣 / 所謂 / 的 / 認 / 同感 / 是 / 我 / 隨便 / 說 / 說 / 而 / 你 / 是否 / 和 / 我 / 一般 / 怯懦 / 是否 / 和 / 我 / 一般 / 矯作 / 是否 / 對 / 你 / 來 / 說 / 只是 / 一場 / 遊戲 / 雖然 / 沒 / 有把握 / 而 / 你 / 是否 / 和 / 我 / 一般 / 退縮 / 是否 / 和 / 我 / 一般 / 肌迫 / 是否 / 對 / 你 / 來 / 說 / 只是 / 逼不得已 / 雖然 / 沒有 / 藉口
我們可以從結果看出斷詞已經開始出了一些問題,比如「座右銘」被斷成了「座 / 右銘」,「墓誌銘」被斷成了「墓誌 / 銘」,這應該就是因為預設詞庫是簡體中文所造成,因此繁體中文的斷詞結果會比較差,還好 jieba 也提供了可以切換詞庫的功能,並提供了一個繁體中文詞庫,所以我們可以使用切換詞庫的功能來改善斷詞結果。
中文歌詞斷詞,使用繁體詞庫
Sample Code:
jieba_cut_lyric_zh.py
#encoding=utf-8
import jieba
jieba.set_dictionary('dict.txt.big')
content = open('lyric.txt', 'rb').read()
print "Input:", content
words = jieba.cut(content, cut_all=False)
print "Output 精確模式 Full Mode:"
for word in words:
print word
我們在程式中多加一行 jieba.set_dictionary(‘dict.txt.big’),這樣就可以將斷詞詞庫切換到 dic.txt.big 這個檔案。
得到的斷詞結果會是:
我 / 沒有 / 心 / 我 / 沒有 / 真實 / 的 / 自我 / 我 / 只有 / 消瘦 / 的 / 臉孔 / 所謂 / 軟弱 / 所謂 / 的 / 順從 / 一向 / 是 / 我 / 的 / 座右銘 / 而 / 我 / 沒有 / 那 / 海洋 / 的 / 寬闊 / 我 / 只要 / 熱情 / 的 / 撫摸 / 所謂 / 空洞 / 所謂 / 不安全感 / 是 / 我 / 的 / 墓誌銘 / 而 / 你 / 是否 / 和 / 我 / 一般 / 怯懦 / 是否 / 和 / 我 / 一般 / 矯作 / 和 / 我 / 一般 / 囉唆 / 而 / 你 / 是否 / 和 / 我 / 一般 / 退縮 / 是否 / 和 / 我 / 一般 / 肌迫 / 一般 / 地 / 困惑 / 我 / 沒有 / 力 / 我 / 沒有 / 滿腔 / 的 / 熱火 / 我 / 只有 / 滿肚 / 的 / 如果 / 所謂 / 勇氣 / 所謂 / 的 / 認同感 / 是 / 我 / 隨便說說 / 而 / 你 / 是否 / 和 / 我 / 一般 / 怯懦 / 是否 / 和 / 我 / 一般 / 矯作 / 是否 / 對 / 你 / 來說 / 只是 / 一場 / 遊戲 / 雖然 / 沒有 / 把握 / 而 / 你 / 是否 / 和 / 我 / 一般 / 退縮 / 是否 / 和 / 我 / 一般 / 肌迫 / 是否 / 對 / 你 / 來說 / 只是 / 逼不得已 / 雖然 / 沒有 / 藉口
我們可以看到「座右銘」成功斷成「座右銘」了!「墓誌銘」也成功斷成「墓誌銘」了!果然切換成繁體中文詞庫還是有用的!
台語歌詞斷詞,使用繁體詞庫
既然中文歌詞斷詞能夠得到不錯的斷詞結果了,那我們來試試看台語歌詞斷詞會是如何?在這邊我們使用 滅火器 - 島嶼天光 的歌詞作為台語斷詞測試範例,歌詞我們先做成一個純文字檔,內容如下:
lyric_tw.txt
親愛的媽媽
請你毋通煩惱我
原諒我
行袂開跤
我欲去對抗袂當原諒的人
歹勢啦
愛人啊
袂當陪你去看電影
原諒我
行袂開跤
我欲去對抗欺負咱的人
天色漸漸光
遮有一陣人
為了守護咱的夢
成做更加勇敢的人
天色漸漸光
已經不再驚惶
現在就是彼一工
換阮做守護恁的人
已經袂記
是第幾工
請毋通煩惱我
因為阮知道
無行過寒冬
袂有花開的一工
天色漸漸光
天色漸漸光
已經是更加勇敢的人
天色漸漸光
咱就大聲來唱著歌
一直到希望的光線
照光島嶼每一個人
天色漸漸光
咱就大聲來唱著歌
日頭一爬上山
就會使轉去啦
現在是彼一工
勇敢的台灣人
Sample Code:
jieba_cut_lyric_zh_tw.py
#encoding=utf-8
import jieba
jieba.set_dictionary('dict.txt.big')
content = open('lyric_tw.txt', 'rb').read()
print "Input:", content
words = jieba.cut(content, cut_all=False)
print "Output 精確模式 Full Mode:"
for word in words:
print word
得到的斷詞結果會是:
親愛 / 的 / 媽媽 / 請 / 你 / 毋通 / 煩惱 / 我 / 原諒 / 我 / 行袂 / 開跤 / 我 / 欲 / 去 / 對抗 / 袂 / 當 / 原諒 / 的 / 人 / 歹勢 / 啦 / 愛人 / 啊 / 袂 / 當 / 陪你去 / 看 / 電影 / 原諒 / 我 / 行袂 / 開跤 / 我 / 欲 / 去 / 對抗 / 欺負 / 咱 / 的 / 人 / 天色 / 漸漸 / 光 / 遮有 / 一陣 / 人 / 為 / 了 / 守護 / 咱 / 的 / 夢 / 成 / 做 / 更加 / 勇敢的人 / 天色 / 漸漸 / 光 / 已經 / 不再 / 驚惶 / 現在 / 就是 / 彼一工 / 換阮 / 做 / 守護 / 恁 / 的 / 人 / 已經 / 袂 / 記 / 是 / 第幾 / 工 / 請 / 毋通 / 煩惱 / 我 / 因為 / 阮 / 知道 / 無行過 / 寒冬 / 袂 / 有 / 花開 / 的 / 一工 / 天色 / 漸漸 / 光 / 天色 / 漸漸 / 光 / 已經 / 是 / 更加 / 勇敢的人 / 天色 / 漸漸 / 光 / 咱 / 就 / 大聲 / 來 / 唱 / 著歌 / 一直 / 到 / 希望 / 的 / 光線 / 照光 / 島嶼 / 每 / 一個 / 人 / 天色 / 漸漸 / 光 / 咱 / 就 / 大聲 / 來 / 唱 / 著歌 / 日頭 / 一爬 / 上山 / 就 / 會 / 使 / 轉去 / 啦 / 現在 / 是 / 彼 / 一工 / 勇敢 / 的 / 台灣 / 人
原本猜想結果應該會蠻差的,畢竟詞庫中沒有台語的用詞,但是因為 HMM 的關係猜出了一些新詞,讓我們還是得到不錯的結果,「袂當」斷成了「袂」「當」,「袂記」斷成了「袂」「記」,「袂有」斷成了「袂」「有」等等,我們要如何改善這些結果呢?
jieba 提供了一個功能讓使用者可以增加自定義詞庫,這種無法用 HMM 判斷出來的新詞就可以得到改善,我們就來試試看吧!
台語歌詞斷詞,使用繁體詞庫加自定義詞庫
首先我們新增一個純文字檔建立自定義詞庫,格式如下:
userdict.txt
行袂開跤 2 v
袂當 4 d
袂記 4 v
袂有 4 d
唱著 4 v
每一個 4 m
會使 70 d
其中每一行代表一筆語料資料,首先填上自定義詞如:「袂當」、「袂記」,然後填上權重,權重值可以依照斷詞結果做自己想做的調整,最後填上詞性,但詞性非必要填寫,詞性列表可以參考 词性对照说明.中科院版本。
Sample Code:
jieba_cut_lyric_zh_tw_custom.py
#encoding=utf-8
import jieba
jieba.set_dictionary('dict.txt.big')
jieba.load_userdict("userdict.txt")
content = open('lyric_tw.txt', 'rb').read()
print "Input:", content
words = jieba.cut(content, cut_all=False)
print "Output 精確模式 Full Mode:"
for word in words:
print word
我們在程式中多加一行 jieba.load_userdict(“userdict.txt”),這樣就可以將自定義詞庫加進來了,超級簡單的。
得到的斷詞結果會是:
親愛 / 的 / 媽媽 / 請 / 你 / 毋通 / 煩惱 / 我 / 原諒 / 我 / 行袂開跤 / 我 / 欲 / 去 / 對抗 / 袂當 / 原諒 / 的 / 人 / 歹勢 / 啦 / 愛人 / 啊 / 袂當 / 陪你去 / 看 / 電影 / 原諒 / 我 / 行袂開跤 / 我 / 欲 / 去 / 對抗 / 欺負 / 咱 / 的 / 人 / 天色 / 漸漸 / 光 / 遮有 / 一陣 / 人 / 為 / 了 / 守護 / 咱 / 的 / 夢 / 成 / 做 / 更加 / 勇敢的人 / 天色 / 漸漸 / 光 / 已經 / 不再 / 驚惶 / 現在 / 就是 / 彼一工 / 換阮 / 做 / 守護 / 恁 / 的 / 人 / 已經 / 袂記 / 是 / 第幾 / 工 / 請 / 毋通 / 煩惱 / 我 / 因為 / 阮 / 知道 / 無行過 / 寒冬 / 袂有 / 花開 / 的 / 一工 / 天色 / 漸漸 / 光 / 天色 / 漸漸 / 光 / 已經 / 是 / 更加 / 勇敢的人 / 天色 / 漸漸 / 光 / 咱 / 就 / 大聲 / 來 / 唱著 / 歌 / 一直 / 到 / 希望 / 的 / 光線 / 照光 / 島嶼 / 每 / 一個 / 人 / 天色 / 漸漸 / 光 / 咱 / 就 / 大聲 / 來 / 唱著 / 歌 / 日頭 / 一爬 / 上山 / 就 / 會使 / 轉去 / 啦 / 現在 / 是 / 彼 / 一工 / 勇敢 / 的 / 台灣 / 人
完美!
取出斷詞詞性
大部份的斷詞系統都可以列出斷詞的詞性,jieba 也有這個功能,但結果可能不是那麼好,這其實是跟所使用的語料庫有關係,不過既然是 Open Source,希望未來能有語言學家可以加入,讓 jieba 可以得到更好的效果。
Sample Code:
jieba_cut_lyric_zh_flag.py
#encoding=utf-8
import jieba
import jieba.posseg as pseg
jieba.set_dictionary('dict.txt.big')
content = open('lyric.txt', 'rb').read()
print "Input:", content
words = pseg.cut(content)
print "Output 精確模式 Full Mode:"
for word in words:
print word.word, word.flag
得到的結果會是:
我 r
沒有 x
心 n
我 r
沒有 x
真實 x
的 uj
自我 r
...
取出斷詞位置
有時我們會需要得到斷詞在文章中的位置:
Sample Code:
jieba_cut_lyric_zh_tokenize.py
#encoding=utf-8
import jieba
jieba.set_dictionary('dict.txt.big')
content = open('lyric.txt', 'rb').read()
print "Input:", content
words = jieba.tokenize(unicode(content, 'utf-8'))
print "Output 精確模式 Full Mode:"
for tk in words:
print "word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2])
得到的結果會是:
word 我 start: 0 end:1
word 沒有 start: 1 end:3
word 心 start: 3 end:4
word start: 4 end:5
word 我 start: 5 end:6
word 沒有 start: 6 end:8
word 真實 start: 8 end:10
word 的 start: 10 end:11
word 自我 start: 11 end:13
...
取出文章中的關鍵詞
jieba 使用了 tf-idf 方法來實作萃取出文章中關鍵詞的功能:
Sample Code:
jieba_cut_lyric_zh_keyword.py
#encoding=utf-8
import jieba
import jieba.analyse
jieba.set_dictionary('dict.txt.big')
content = open('lyric.txt', 'rb').read()
print "Input:", content
tags = jieba.analyse.extract_tags(content, 10)
print "Output:"
print ",".join(tags)
程式中的 jieba.analyse.extract_tags(content, 10),就是告訴 jieba 我們要從這個文章中取出前 10 個 tf-idf 值最大的關鍵詞。
得到的結果會是:
沒有,所謂,是否,一般,雖然,退縮,肌迫,矯作,來說,怯懦
一開始使用這個功能的時候,會不知道 jieba 的 idf 值是從哪裡來的,看了一下 souce code 才知道原來 jieba 有提供一個 idf 的語料庫,但在實務上每個人所使用的語料庫可能會不太一樣,有時我們會想要使用自己的idf 語料庫,stop words 的語料庫也可能會想換成自己的,比如目前的結果中,最重要的「座右銘」並沒有出現在關鍵詞裡,我就會想要將「座右銘」加到 idf 語料庫,並讓 idf 值高一點,而「沒有」這個關鍵詞對我來說是沒有用的,我就會想把它加到 stop words 語料庫,這樣「沒有」就不會出現在關鍵詞裡。
可惜目前 pip 安裝的 jieba 版本並不能切換 idf 及 stop words 語料庫,所以我才會修改了一下 jieba,讓它可以支援 idf 及 stop words 語料庫的切換,目前在 github 上的版本已經可以支援 idf 及 stop words 切換的功能了!
結語
使用了 jieba 之後,其實有蠻深的感嘆,其實中研院的斷詞核心必非不好,想要收費也不是問題,但是 API 做得這麼差,根本就沒人有信心敢花錢下去使用這樣不可靠的系統,目前又有 jieba 這樣的 open source project,中研院的斷詞系統前途堪慮啊!
後記 2017/07/18
我後來有好幾次受邀演講關於中文斷詞的講題,相關的投影片都有分享在網路上了,大家也可以交叉參考:中文斷詞:斷句不要悲劇 / Head first Chinese text segmentation 投影片、範例程式碼。