前言
本系列部落格文章將分享我在 Coursera 上台灣大學林軒田教授所教授的機器學習基石(Machine Learning Foundations)課程整理成的心得,並對照林教授的投影片作說明。若還沒有閱讀過 第二講 的碼農們,我建議可以先回頭去讀一下再回來喔!
第三講的內容偏向介紹各種機器學習方法,以前念論文的時候看到這些名詞都會覺得高深莫測,但其實這各式各樣的機器學習方法其實都是從最基礎的核心變化而來,所以不要被嚇到。了解各種機器學習方法的輸入輸出對於日後面對一些問題的時候,我們才能夠知道要挑選什麼機器學習方法來解決問題。
範例原始碼:FukuML - 簡單易用的機器學習套件
我在分享機器學習基石課程時,也跟著把每個介紹過的機器學習演算法都實作了一遍,原始碼都放在 GitHub 上了,所以大家可以去參考看看每個演算法的實作細節,看完原始碼會對課程中的數學式更容易理解。
如果大家對實作沒有興趣,只想知道怎麼使用機器學習演算法,那 FukuML 絕對會比起其他機器學習套件簡單易用,且方法及變數都會跟林軒田教授的課程類似,有看過課程的話,說不定連文件都不用看就會使用 FukuML 了。不過我還是有寫 Tutorial 啦,之後會不定期更新,讓大家可以容易上手比較重要!
熱身回顧一下
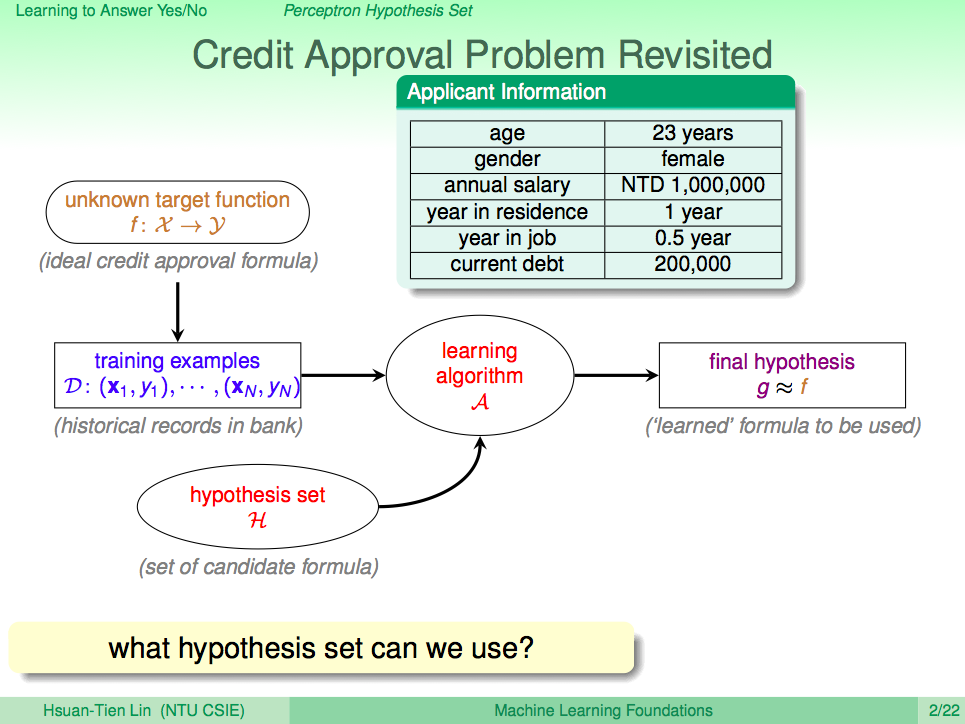
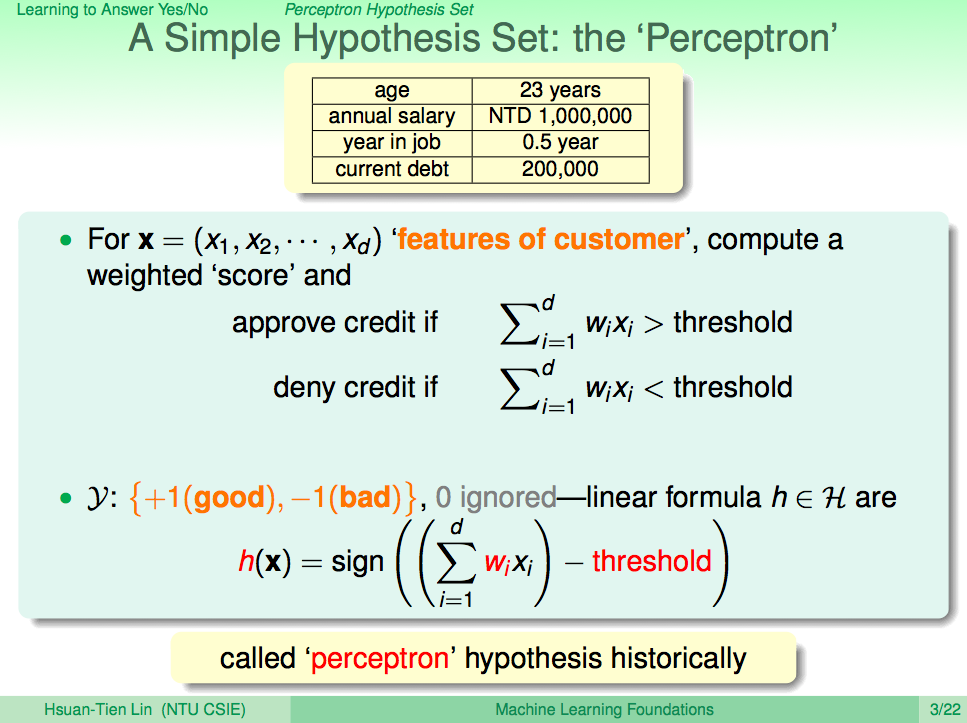
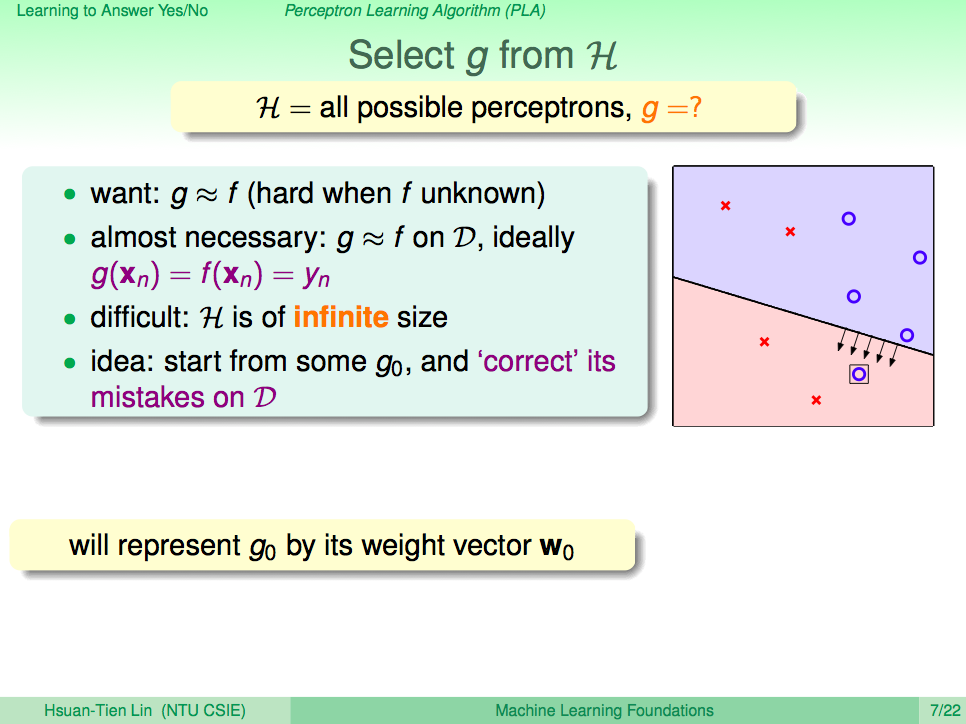
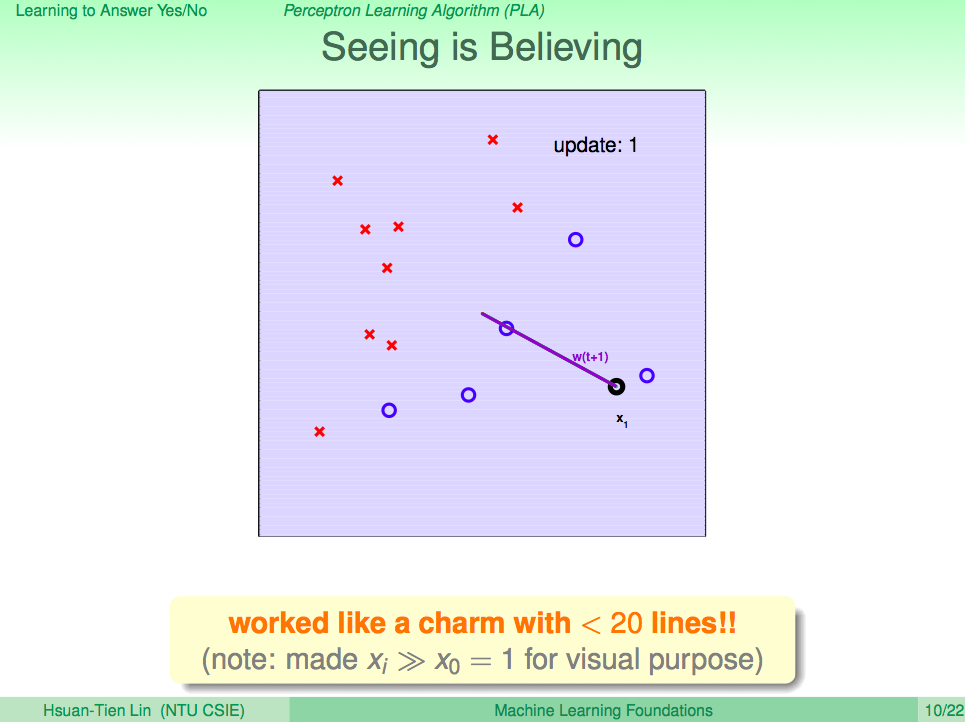
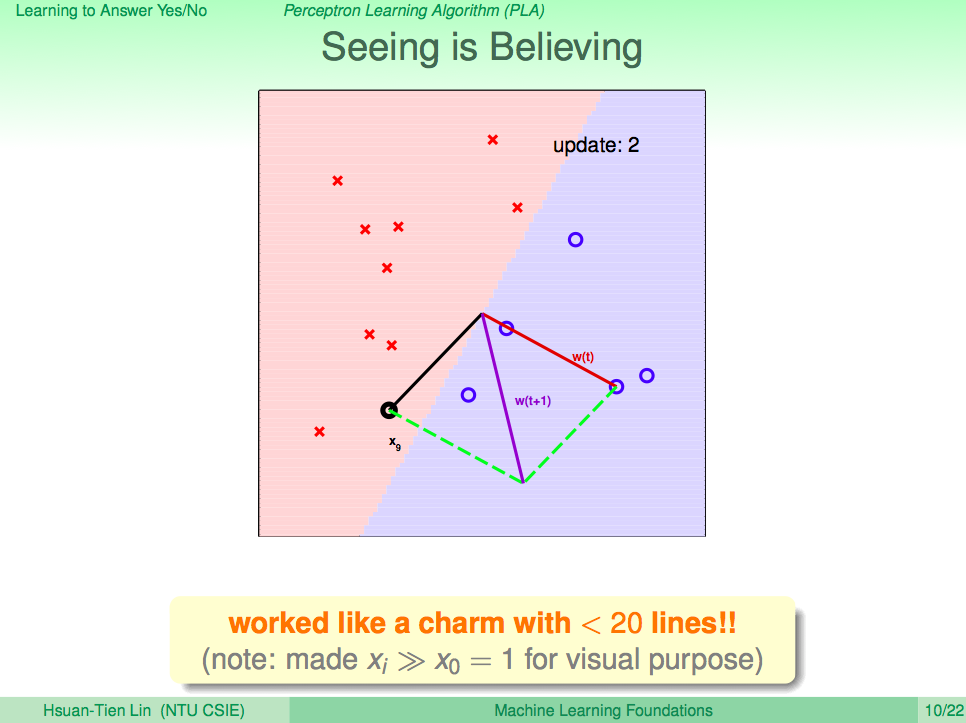
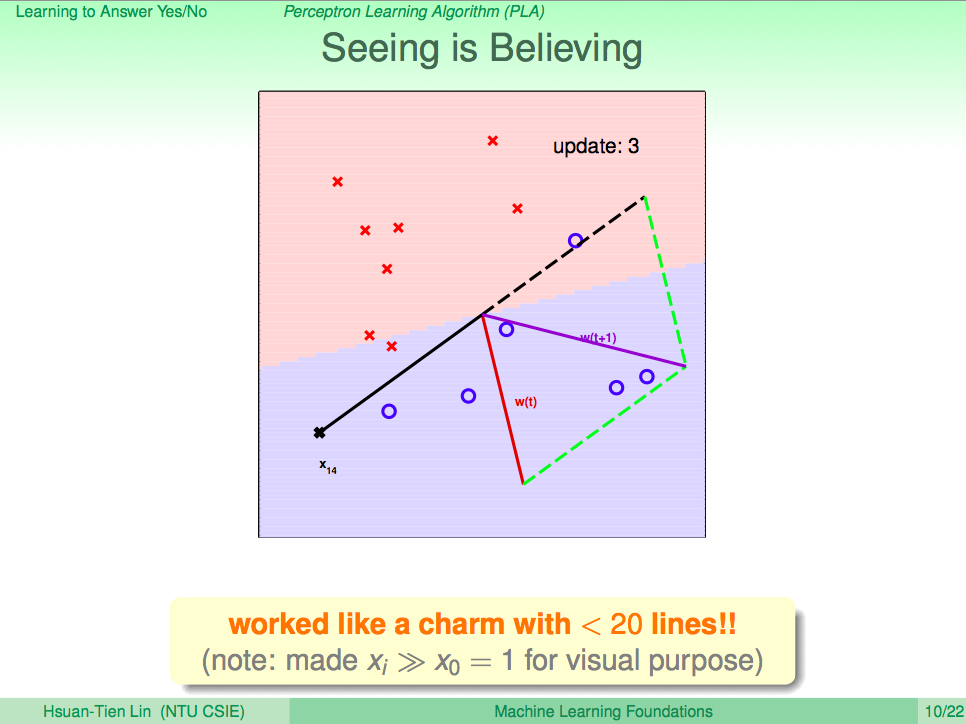
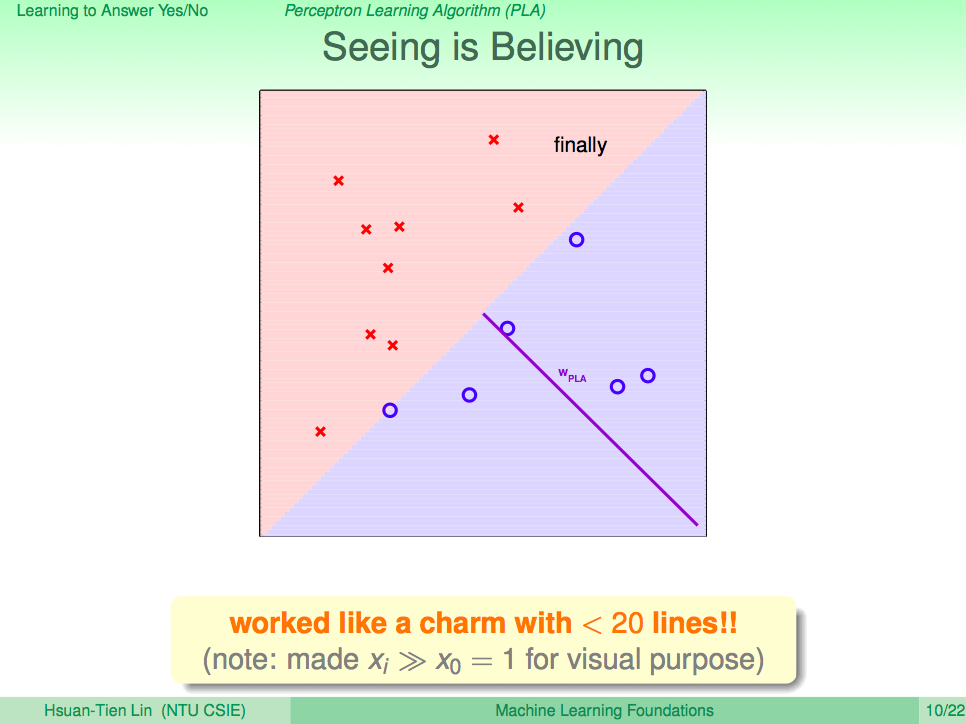
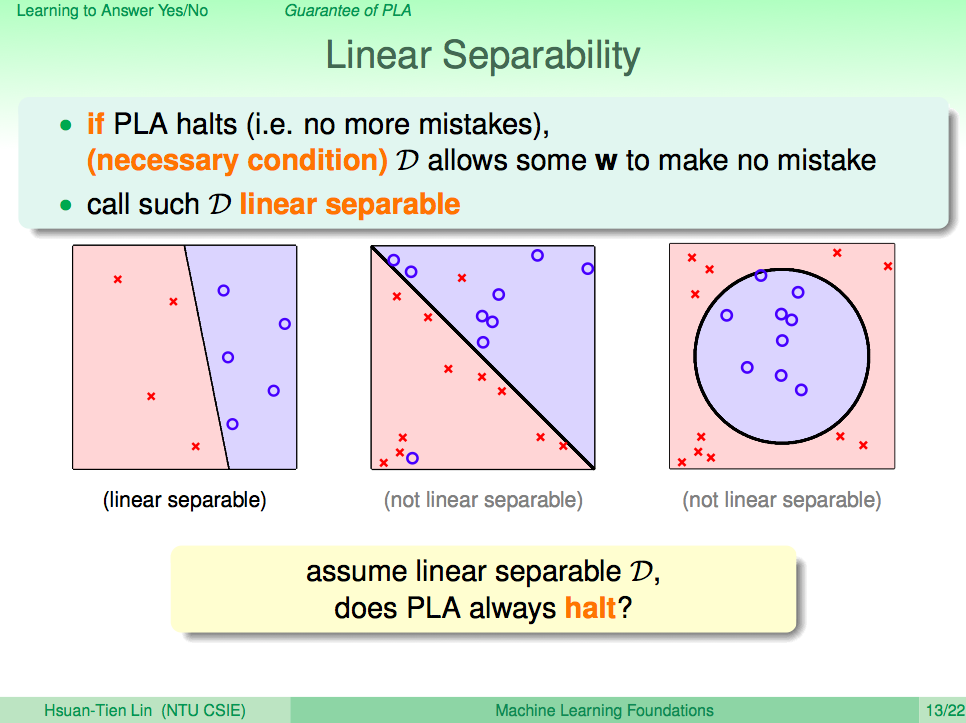
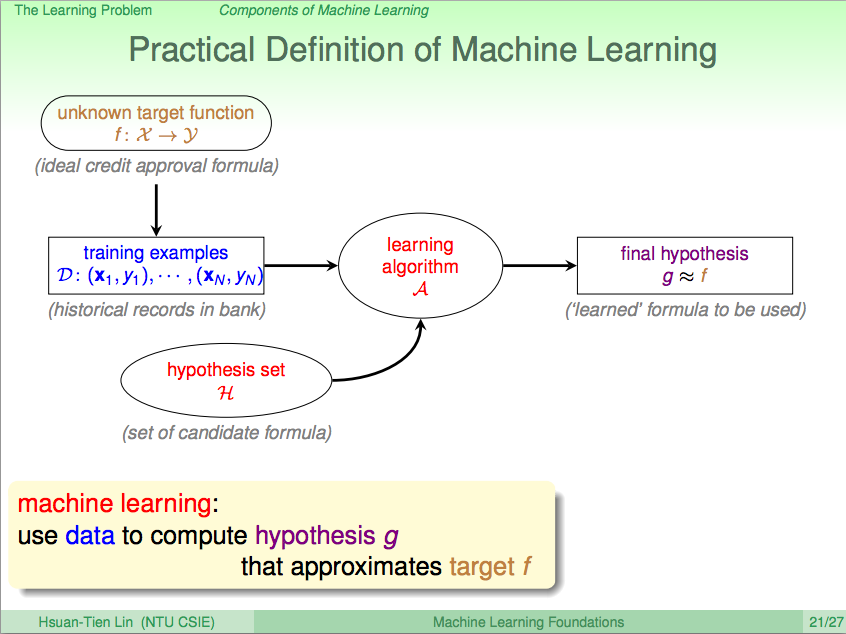
我們先來回顧一下上一講的內容,在上一講我們知道了如何使用 PLA 讓機器學會回答是非題這樣的兩類問題(Binary Classificaction),套到機器學習的那句名句,我們可以清楚的了解,PLA 這個演算法 A 觀察了線性可分(linear separable)的 D 及感知假設集合 H 去得到一個最好的假設 g,這一句話就可以概括到上一講的內容了。

從輸出 y 的角度看機器學習,y 只有兩個答案選一個,就叫 Binary Classification
接下來我們來了解一下各式各樣的學習方法,從輸出 y 的角度看機器學習,y 只有兩個答案選一個,就叫 Binary Classification,像是之前的是否發信用卡的例子就是 Binary Classification。
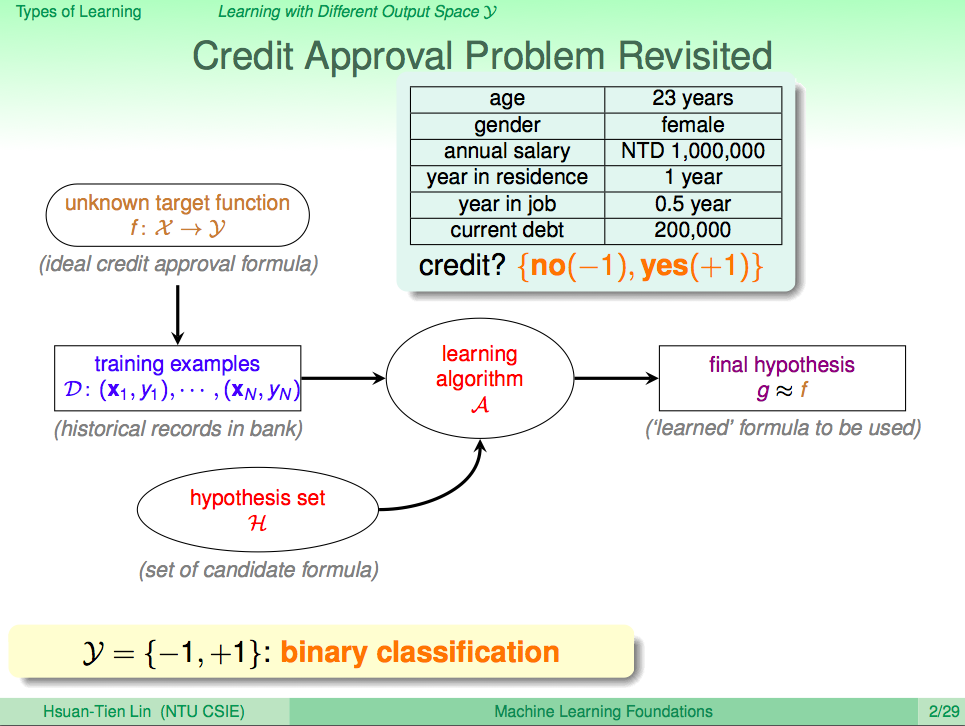
從輸出 y 的角度看機器學習,y 有多個答案選一個,就叫 Multiclass Classification
從輸出 y 的角度看機器學習,y 有多個答案選一個,就叫 Multiclass Classification,像是使用投飲機辨識錢幣的問題就是一個 Multiclass Classification 的問題,所以我們可以將分類問題推廣到分成 K 類,這樣 Binary Classificatin 就是一個 K=2 的分類問題。
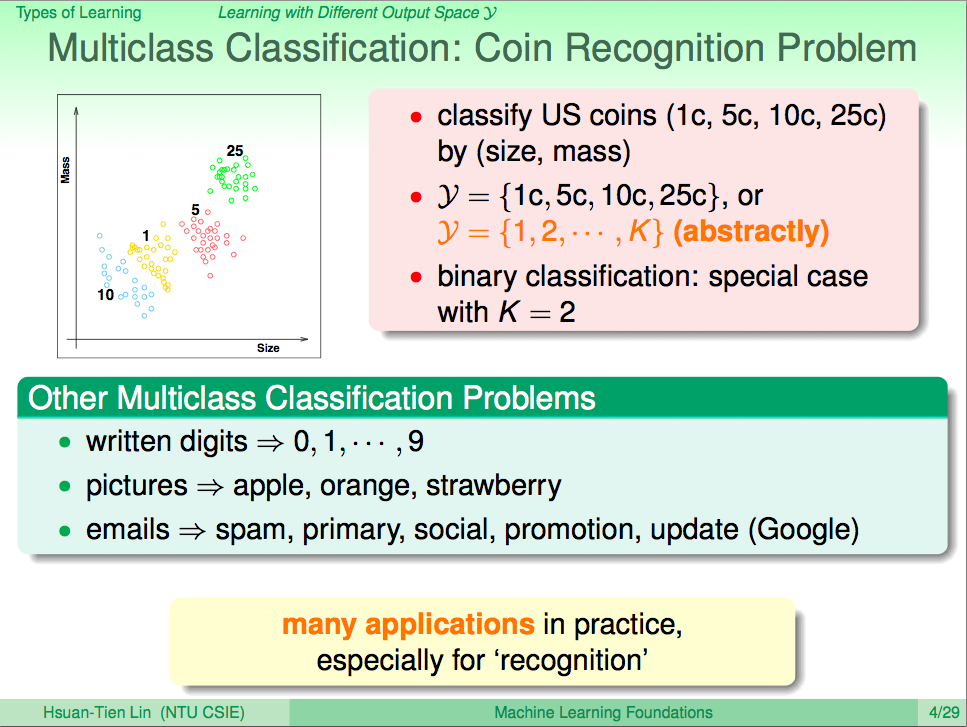
從輸出 y 的角度看機器學習,y 為一個實數,就叫 Regression
從輸出 y 的角度看機器學習,y 為一個實數,就叫 Regression,像是要預估病人再過幾天病會好,這就需要用到 Regression,這也會用到許多統計學相關的工具。
從輸出 y 的角度看機器學習,y 為一個結構序列,就叫 Structured Learning
從輸出 y 的角度看機器學習,y 為一個結構序列,就叫 Structured Learning,比如一個句子的詞性分析,會需要考慮到句子中的前後文,而句子的組合可能有無限多種,因此不能單純用 Multiclass Classification 來做到,這就需要用到 Structured Learning 相關的機器學習方法。
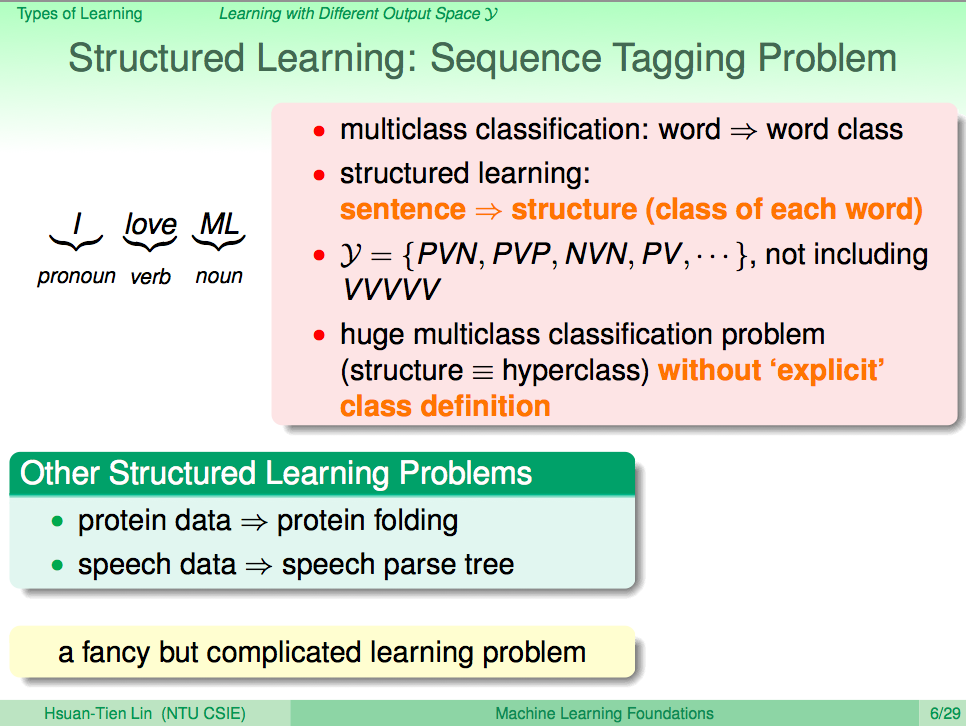
從輸出 y 的角度看機器學習,做個小結
從輸出 y 的角度看機器學習,如果 y 是兩類,那就是 Binary Classification;如果 y 是 k 類,那就是 Multiclass Classification;如果 y 是一個實數,那就是 Regression;如果 y 是一種結構關係,那就是 Structured Learning。當然還有其他變化,不過基礎上就是 Binary Classification 及 Regression,我們可以透過這兩個基礎核心來延伸出其他機器學習方法。
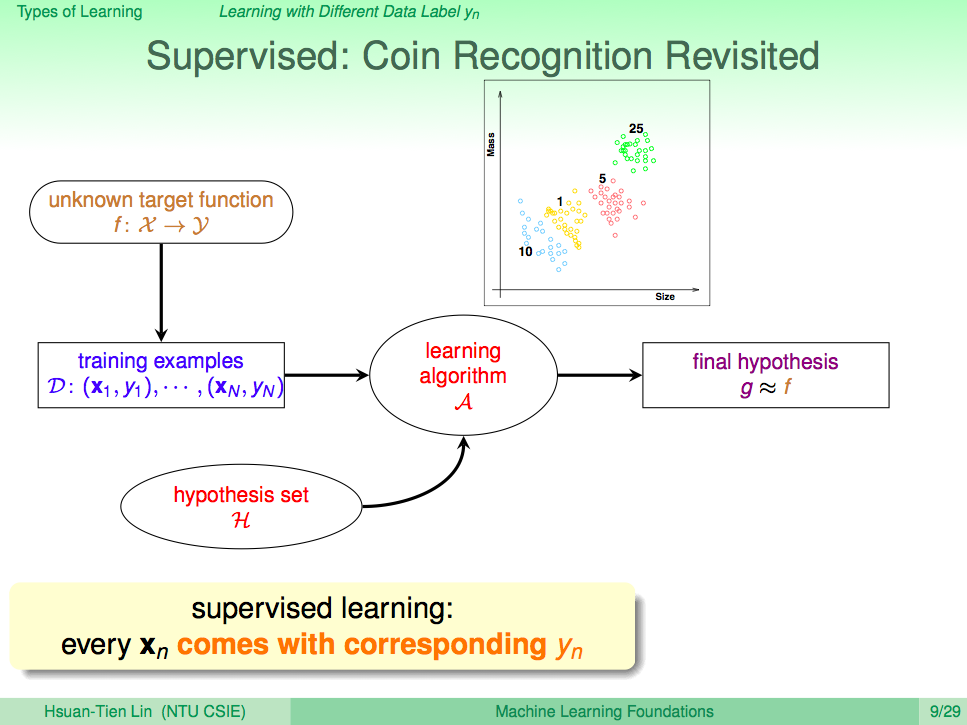
從輸入的資料 Yn 的角度看機器學習,如果每個 Xn 都有明確對應的 Yn,這就叫監督式學習(Supervised Learning)
從輸入的資料 Yn 的角度看機器學習,如果每個 Xn 都有明確對應的 Yn,這就叫監督式學習(Supervised Learning),比如在訓練投飲機辨識錢幣的時候,我們很完整個告訴他什麼大小、什麼重量就是什麼幣值的錢幣,這樣就是一種監督式學習方法。
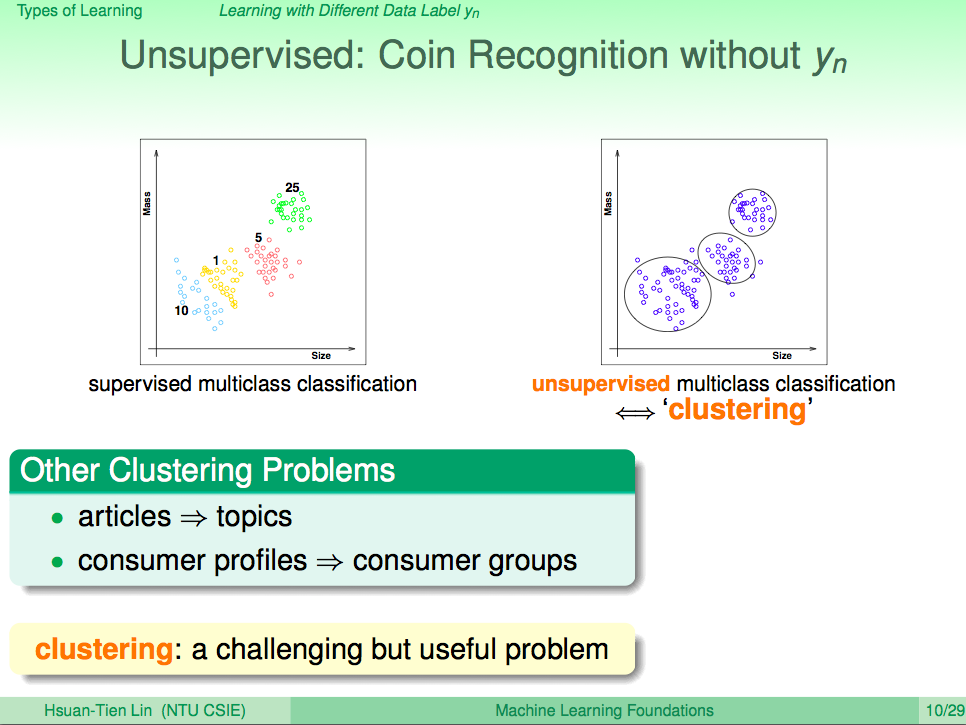
從輸入的資料 Yn 的角度看機器學習,如果每個 Xn 都沒有標示 Yn,這就叫非監督式學習(Unsupervised Learning)
從輸入的資料 Yn 的角度看機器學習,如果每個 Xn 都沒有標示 Yn,這就叫非監督式學習(Unsupervised Learning)。比如在訓練投飲機辨識錢幣的時候,我們只告訴投飲機錢幣的大小及重量,但不告訴他什麼大小及重量個錢幣是哪個幣值的錢幣,讓機器自己去觀察特徵將這些錢幣分成一群一群,這又叫做分群,這就是一種非監督式學習方法。
從輸入的資料 Yn 的角度看機器學習,如果 Xn 只有部分有標示 Yn,這就叫半監督式學習(Semi-supervised Learning)
從輸入的資料 Yn 的角度看機器學習,如果 Xn 只有部分有標示 Yn,這就叫半監督式學習(Semi-supervised Learning),有些資料較難取得的狀況下,我們會使用到半監度式學習,比如在預測藥物是否對病人有效時,由於做人體實驗成本高且可能要等一段時間來看藥效,這樣的情況下標示藥物有效或沒效的成本很高,所以就可能需要用到半監度式學習。

從輸入的資料 Yn 的角度看機器學習,如果 Yn 是很難確知描述的,只能在機器作出反應時使用處罰及獎勵的方式讓機器知道對或錯,這就叫增強式學習(Reinforcement Learning)
從輸入的資料 Yn 的角度看機器學習,如果 Yn 是很難確知描述的,只能在機器作出反應時使用處罰及獎勵的方式讓機器知道對或錯,這就叫增強式學習(Reinforcement Learning)。這樣的機器學習方式,比較像自然界生物的學習方式,就像你要教一隻狗坐下,你很難直接告訴他怎麼做,而是用獎勵或處罰的方式讓狗狗漸漸知道坐下是什麼。增強式學習也就是這樣的機器學習方法,透過一次一次經驗的累積讓機器能夠學習到一個技能。比如像是教機器學習下棋,我們也可以透過勝負讓機器漸漸學習到如何下棋會下得更好。

從輸入的資料 Yn 的角度看機器學習,做個小結
從輸入的資料 Yn 的角度看機器學習,如果明確告知每個 Yn,那就是監督式學習;如果沒有告知任何 Yn,那就是非監督式學習;如果只有部份 Yn 的資料,那就是半監督式學習;如果是用獎勵、處罰的方式來告知 Yn,那就是增強式學習。當然還有其他種機器學習方法,其中最重要的核心就是監督式學習方法。

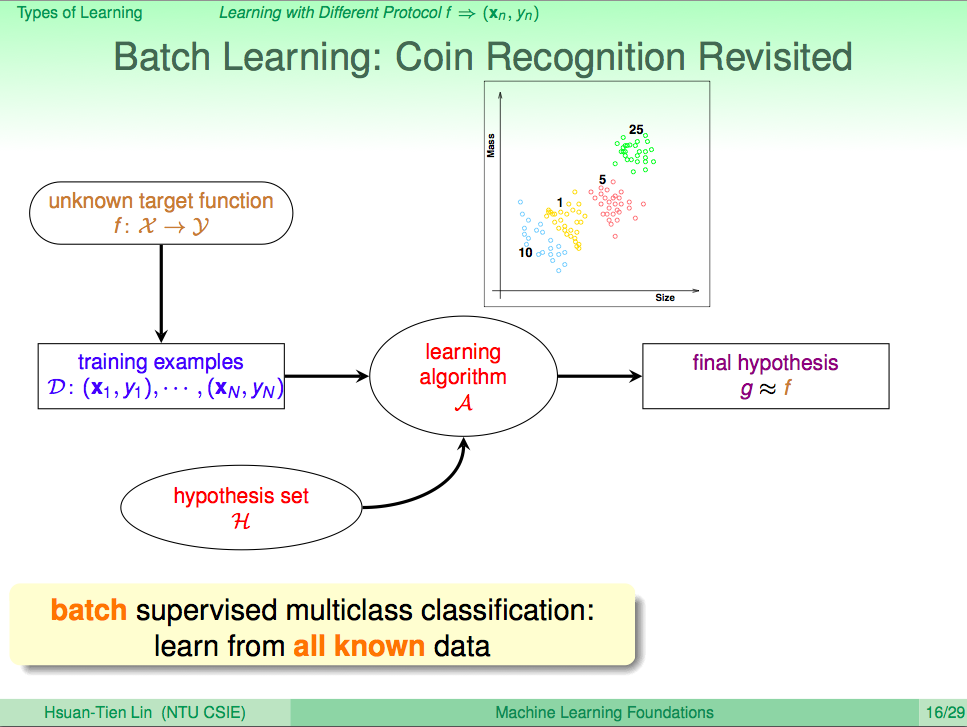
從餵資料給機器的角度看機器學習,一次餵進全部資料,這就叫 Batch Learning
從餵資料給機器的角度看機器學習,一次餵進全部資料,這就叫 Batch Learning。監督式學習方法,可能也會常使用 Batch Learning 的方式為資料。
從餵資料給機器的角度看機器學習,可以再慢慢餵進新資料,這就叫 Online Learning
從餵資料給機器的角度看機器學習,可以再慢慢餵進新資料,這就叫 Online Learning。Batch Learging 訓練好的機器,就無法調整他的技巧,可能會有越來越不準的情況,所以 Online Learning 可以再慢慢調整、增進技巧。PLA 算法可以很容易應用在 Online Learning 上,增強式學習方法也常常是使用 Online Learning 的方式餵資料。

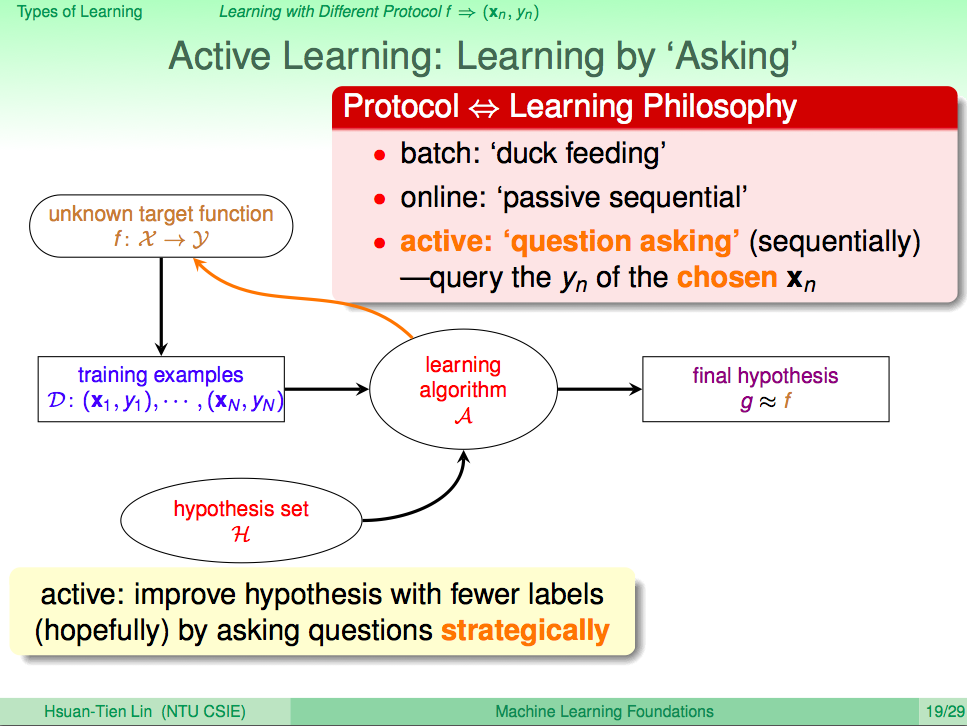
從餵資料給機器的角度看機器學習,機器可以問問題,然後從問題的答案再餵進資料,這就叫 Active Learning
從餵資料給機器的角度看機器學習,機器可以問問題,然後從問題的答案再餵進資料,這就叫 Active Learning。這樣的學習方法是要希望讓機器可以用一些策略問問題,然後慢慢學習、改善技巧。
從餵資料給機器的角度看機器學習,做個小結
從餵資料給機器的角度看機器學習,如果一次餵進所有資料,就叫 Batch Learning;如果後續可以再慢慢餵進資料,就叫 Online Learning;如果機器可以問問題來餵進資料,就叫 Active Learning。當然還有其他種機器學習方法,其中最重要的核心就是 Batch Learning。
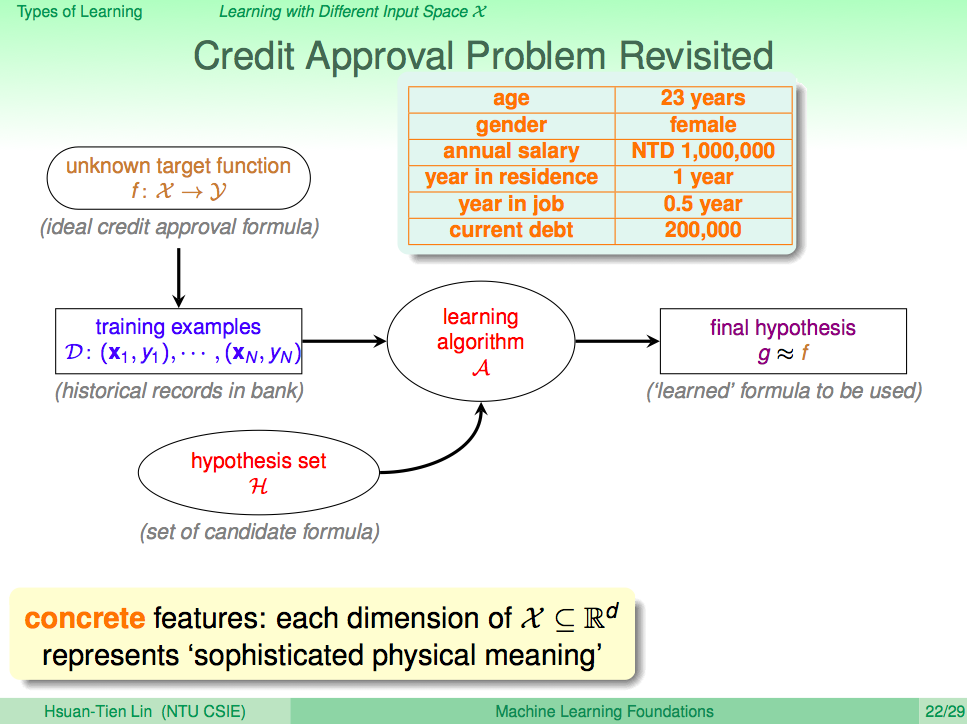
從輸入 X 的角度看機器學習,如果 X 的特徵很明確定義,這就叫 Concrete Feature
從輸入 X 的角度看機器學習,如果 X 的特徵很明確定義,這就叫 Concrete Feature。Concrete Featrue 的取得通常需要人去介入,比如為何發不發信用卡要看申請者的年收入,這就是因為人們覺得年收入對於付不得付出卡費有關係。
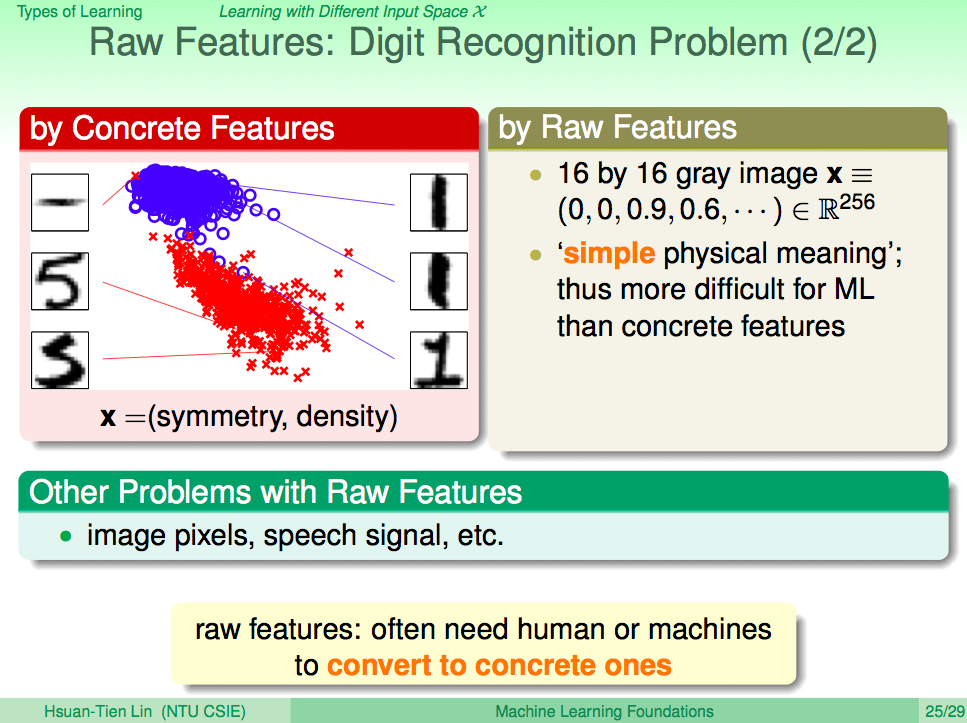
從輸入 X 的角度看機器學習,如果 X 的特徵是用最基礎未人為整理過的,這就叫 Raw Feature
從輸入 X 的角度看機器學習,如果 X 的特徵是用最基礎未人為整理過的,這就叫 Raw Feature。比如聲音訊號的頻率,圖片的像素,這都是 Raw Feature。
從輸入 X 的角度看機器學習,如果 X 的特徵是抽象的像是編號這樣的資料,這就叫 Abstract Feature
從輸入 X 的角度看機器學習,如果 X 的特徵是抽象的像是編號這樣的資料,這就叫 Abstract Feature。這通常就需要有人去抽取出更具象的特徵資料出來,這些特徵可能包含 Concrete Feature 或 Raw Feature。

從輸入 X 的角度看機器學習,做個小結
從輸入 X 的角度看機器學習,如果 X 是明確定義的,那就是 Concrete Feature;如果 X 是未經人為定義過的,那就是 Raw Feature;如果 X 是抽象的編號,那就是 Abstract Feature。當然還有其他種特徵,其中最重要的核心就是 Concrete Feature。
總結
從輸出 y 的角度看機器學習、從輸入的資料 Yn 的角度看機器學習、從餵資料給機器的角度看機器學習、從輸入 X 的角度看機器學習都會有許多不同的機器學習方法,但重要的是了解哪些是核心,其他機器學習方法也都是從這些核心發展而來。