前言
本系列部落格文章將分享我在 Coursera 上台灣大學林軒田教授所教授的機器學習技法(Machine Learning Techniques)課程整理成的心得,並對照林教授的投影片作說明。若還沒有閱讀過 機器學習基石系列 的碼農們,我建議可以先回頭去讀一下再回來喔!
範例原始碼:FukuML - 簡單易用的機器學習套件
我在分享機器學習基石課程時,也跟著把每個介紹過的機器學習演算法都實作了一遍,原始碼都放在 GitHub 上了,所以大家可以去參考看看每個演算法的實作細節,看完原始碼會對課程中的數學式更容易理解。
如果大家對實作沒有興趣,只想知道怎麼使用機器學習演算法,那 FukuML 絕對會比起其他機器學習套件簡單易用,且方法及變數都會跟林軒田教授的課程類似,有看過課程的話,說不定連文件都不用看就會使用 FukuML 了。不過我還是有寫 Tutorial 啦,之後會不定期更新,讓大家可以容易上手比較重要!
熱身回顧一下
從機器學習基石課程中,我們已經了解了機器學習一些基本的演算法,在機器學習技法課程中我們將介紹更多進階的機器學習演算法。首先登場的就是支持向量機(Support Vector Machine)了,第一講中我們將先介紹最簡單的 Hard Margin Linear Support Vector Machine。

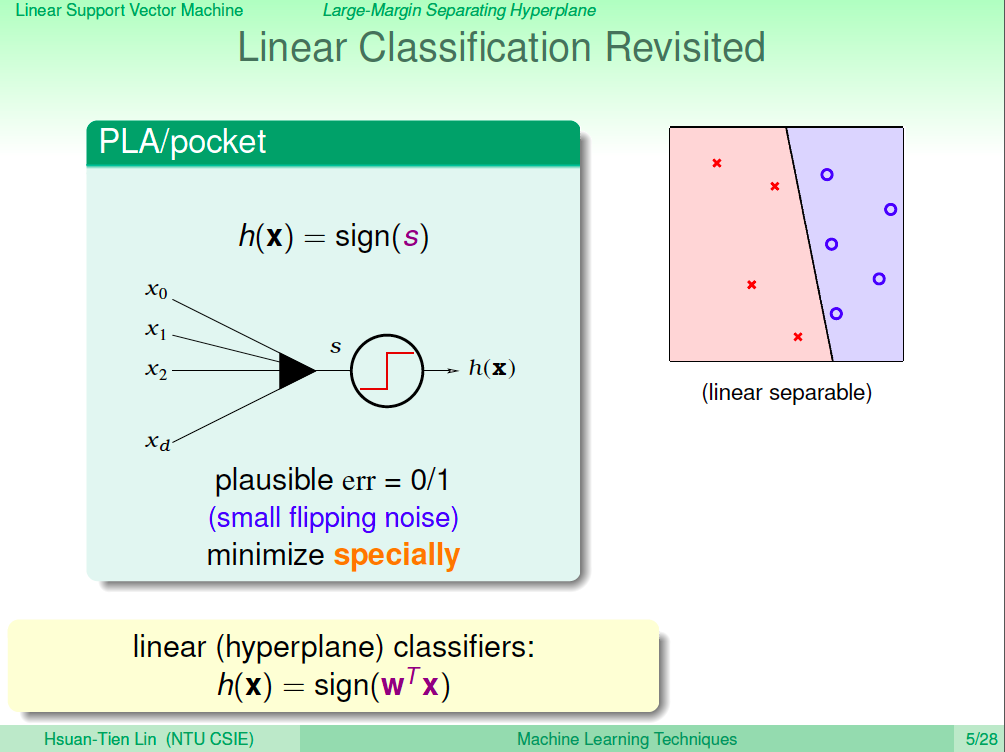
線性分類回憶
回憶一下之前的課程中,我們使用 PLA 及 Pocket 來學習出可以分出兩類的線。
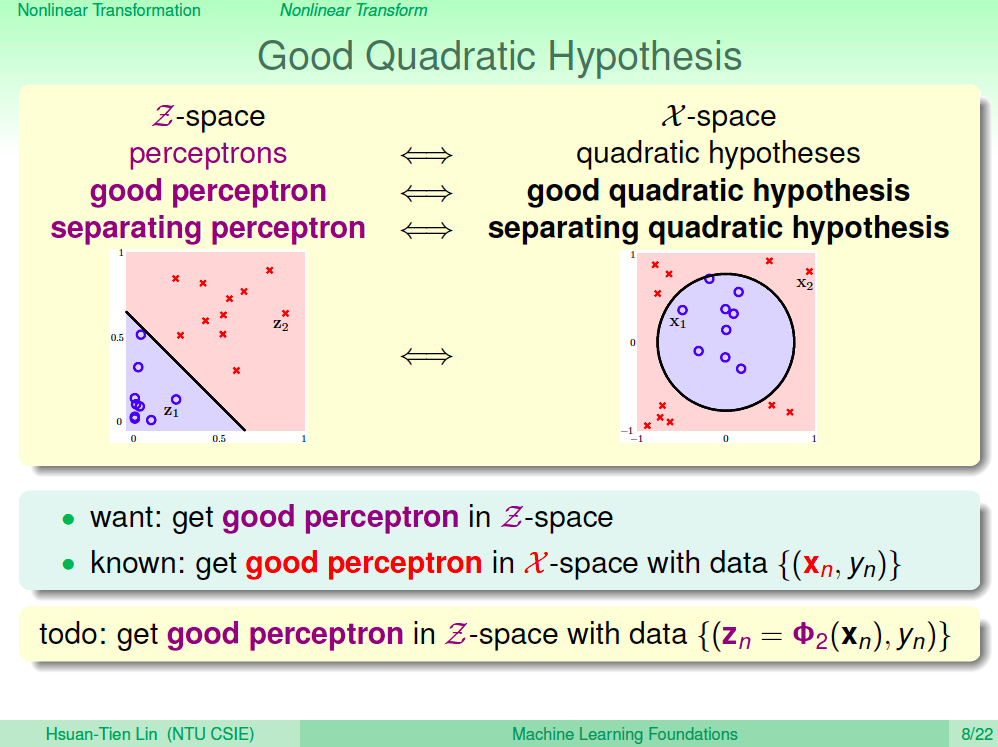
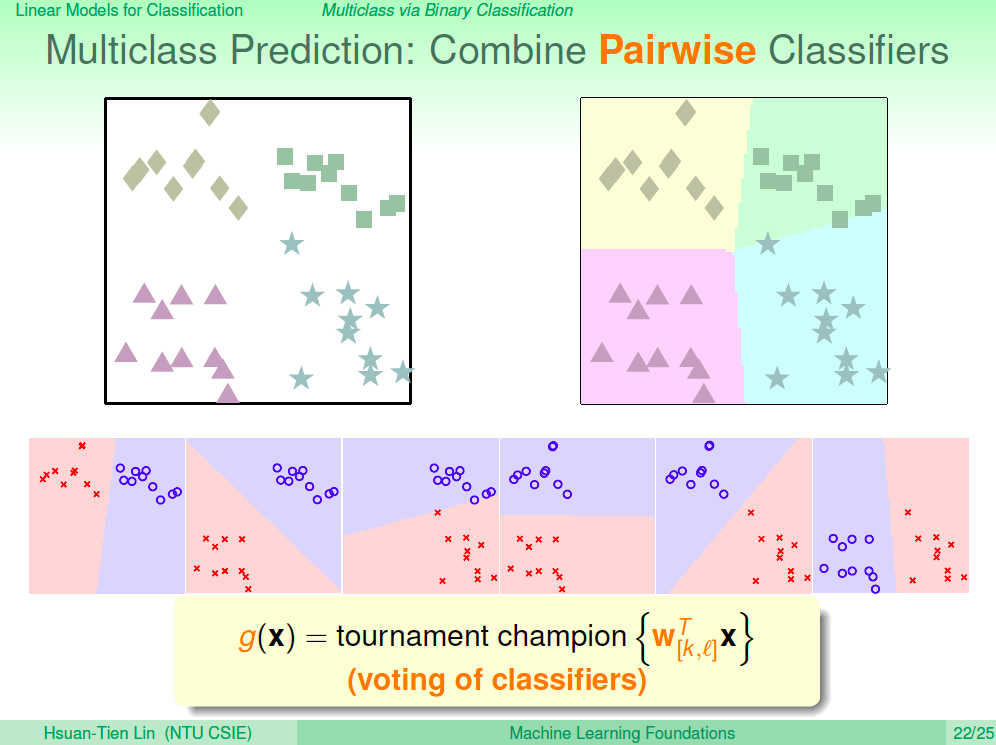
哪條線最好?
但其實可以將訓練資料分類的線可能會有很多條線,如下圖所示。我們要怎麼選呢?如果用眼睛來看,你或許會覺得右邊的這條線最好。

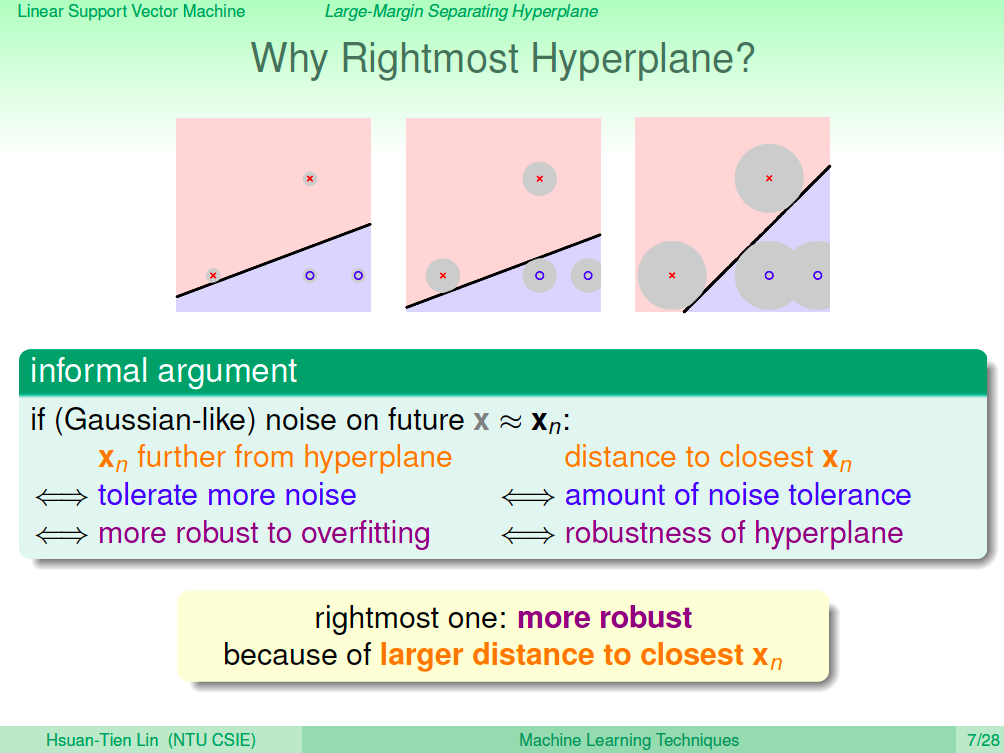
為何右邊這條線最好?
為何會覺得右邊這條線最好呢?假設先在我們再一次取得資料,可以預期資料與訓練資料會有點接近,但並不會完全一樣,這是因為 noise 的原因。所以偏差了一點點的 X 及 O 再左邊這條線可能就會不小心超出現,所以就會被誤判了,但在右邊這條線就可以容忍更多的誤差,也就比較不容易 overfitting,也因此右邊這條線最好。
如何描述這條線?我們可以說這條線與最近的訓練資料距離是所有的線中最大的。
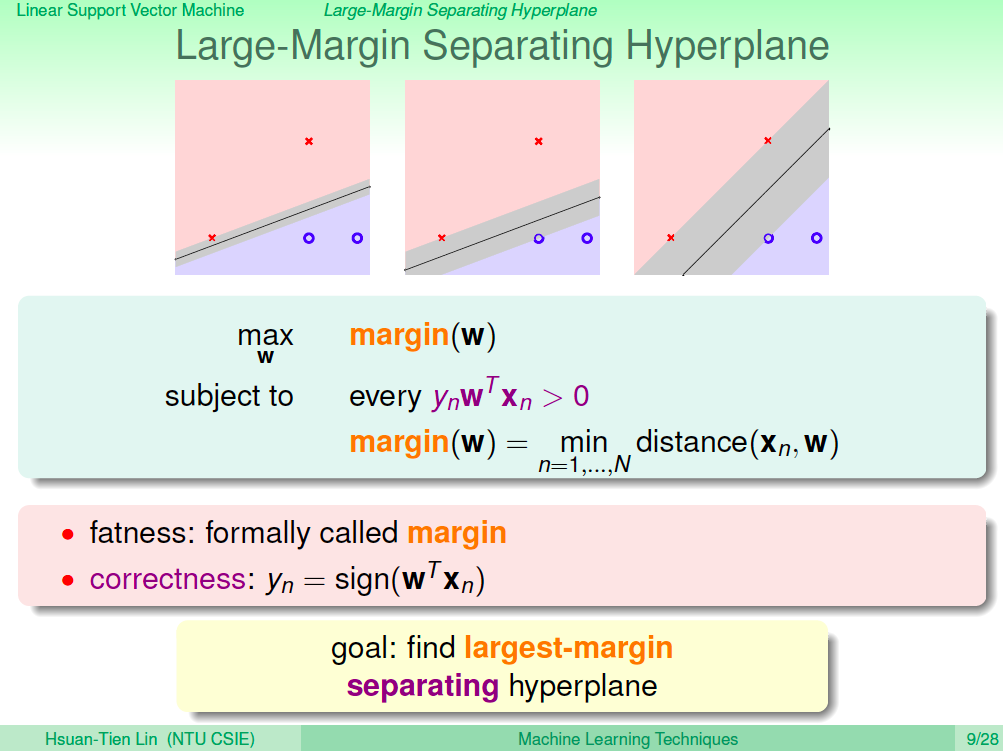
胖的線
我們希望得到的線與最近的資料點的距離最大,換的角度,我們也可以說,我們想要得到最胖的線,而且這個胖線還可以將訓練資料分好分類。

Large-Margin Separating Hyperplane
這種胖的線名稱就叫 Large-Margin Separating Hyperplane,原本的問題就可以定義成要找最大的 margin,而且還要分好類,也就是 yn = sign(wTXn)。
最大的 margin 可以轉換成點與超平面之間最小的距離 distance(Xn, w),然後 yn = sign(wTXn),就代表 Yn 與 score 同號,所以可以轉換成 YnwTXn > 0,我們需要求解滿足這些條件的超平面。
點與超平面的距離 - 符號解釋
點與超平面的距離怎麼算呢?在這邊的推導,我們需要暫時將 w0 分出來,寫成 b,所以我們之前熟悉的 wTXn 在這邊暫時變成 wTxn + b,以方便推導。

點與超平面的距離 - 推導
如果我們現在有一個超平面 wTx + b = 0,假設 x’ 與 x” 都在這個超平面上,也就是 wTx’ + b 及 wTx” + b 都會是 0,如此就會得到 wTx’ = -b 及 wTx” = -b。現在我們將 wT 與 (X”- X’) 相乘,由於剛剛的式子,我們會得到 0。(X”- X’)是一個在 wTx + b = 0 超平面上的向量,W 與這個向量相乘會是 0 就代表 w 是這個超平面的法向量,要算 x 與超平面的距離,就是將 (x-x’) 這個向量投影到 w,就可以算出點與超平面的距離了,公式如下所示。
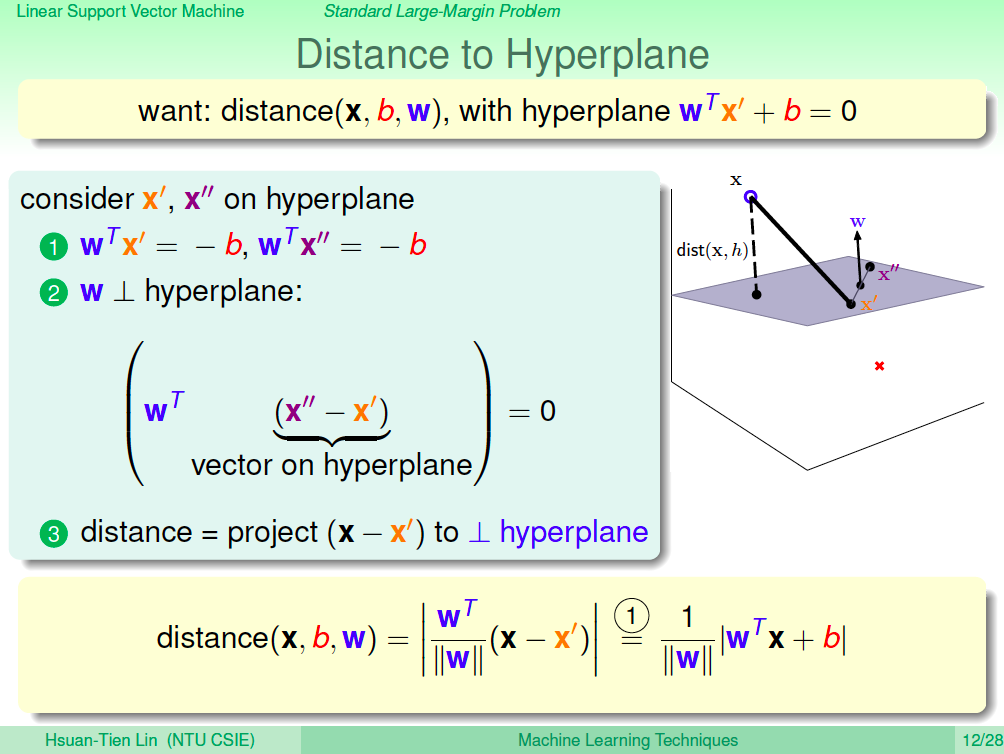
分開訓練資料的超平面
由於我們要求的事可以分開訓練資料的超平面,因此已有 yn(wTXn+ b) > 0 這個條件,也因此距離公式中的 |wTx+b| 可以用 yn(wTXn + b) 來取代,這樣會比較容易求解。

減少超平面解的數量
觀察一下下圖中所有求解的條件,我們可以再進一步簡化。假設我們要找的是 wTx + b = 0 這個超平面,我們對這個超平面進行縮放其實是沒有任何影響的,現在我們也將 wTx + b 進行放縮,讓它跟 yn 相乘會是 1,也就是 yn(wTXn + b) = 1,這樣原本的 margin(b,w) 就是可以轉換成 1 除以 w 的長度,我們只要求讓這個值最大的平面就可以了。

再次簡化問題
經過上述的推導,我們的問題變成求滿足(1) max 1/||w|| 及 (2) min yn(wTXn + b) = 1 這兩個條件的超平面,但這樣我們好像還是覺得有些複雜不會解,可以再這麼簡化呢?
min yn(wTXn + b) = 1 這個條件我們可以讓它的限制再鬆一點,只要 yn(wTxn+b)>=1 就好了,理論上保證最後得到的解,一定會有等於 1 的情況,而不會全部都大於 1。
另外 max 1/||w|| 我們改成 min ||w||,||w|| 是 wTw 開根號,我們可以不理根號然後乘上 1⁄2 以方便後面的推導,所以轉換成 min 1⁄2(wTw)。

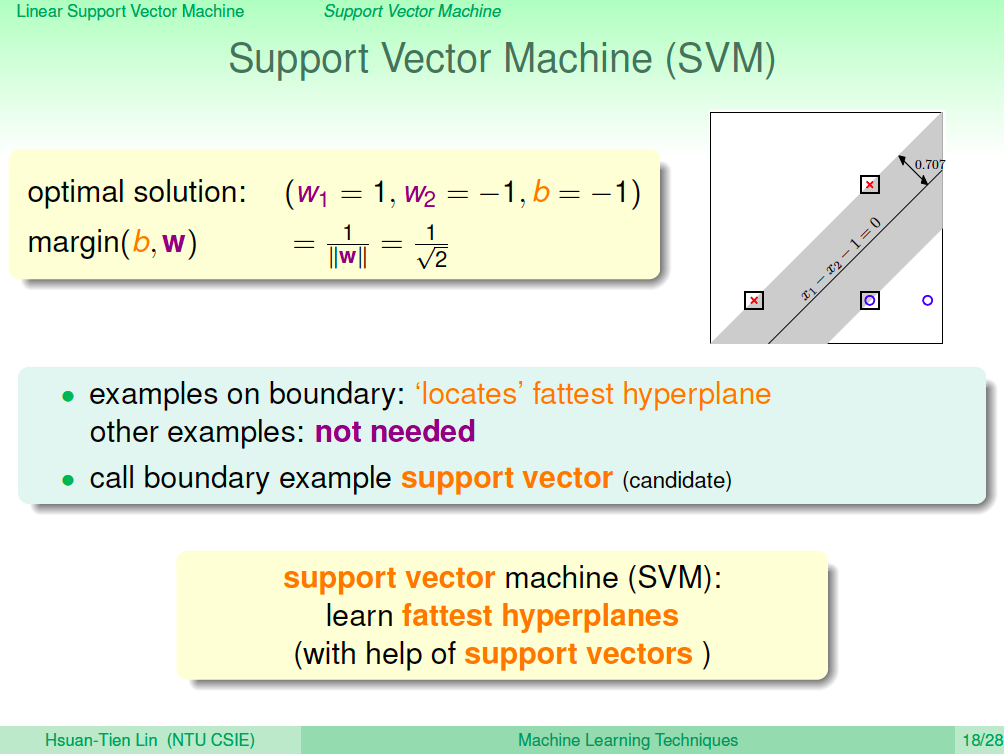
解一個簡單的問題來看看
現在我們求解的條件變成求 min 1⁄2(wTw) 且 yn(wTXn + b)>=1 的超平面,我們用一個簡單的例子來求解看看。如下圖所示,我們可以找出 w1 = 1, w2 = -1, b = -1 滿足我們的條件,這個超平面就是 x1 - x2 - 1,這個超平面也稱為 Support Vector Machine(SVM)。

支持向量機(Support Vector Machine)
從上面這個簡單例子,讓我們來了解一下支持向量機。首先,這個向量可以由 margin 的公式得出 marging 的寬度值。我們會發現有些點會剛好在這個 margin 的邊界上,這些點就是所謂的支持向量(Support Vector)。這些支持向量可以標出胖線的位置,其他的點則無法,所以其他的點在這個問題上是不重要的點。
所以 SVM 的意思就是:透過 Support Vector 的協助來學習出最胖的超平面。
實際上怎麼解這個問題?
我們剛剛只是從一個簡單的例子來解 SVM,那實際上怎麼解這個問題呢?之前我們學過 gradient descent,在這邊好像沒用,因為有很多限制,我們不能讓演算法自由自在的計算 gradient descent。
但這個問題其實有現存的方法可以解,觀察所有的限制式就會發現 SVM 可以用二次規劃(quadratic programming)來找出最佳解。

二次規劃
我們把 SVM 的限制式,跟二次規劃的限制式做一個比較,就發現可以將問題轉換成二次規劃的相關參數,找出 SVM 問題在二次規劃時的 u, Q, p, a, c,我們就可以把這些參數丟到 QP Solver 來幫我們解 SVM。
目前各語言都有提供 QP Solver,但是介面參數可能會不相同,要自己讀文件去了解各個參數,自己做轉換。

第一個 SVM
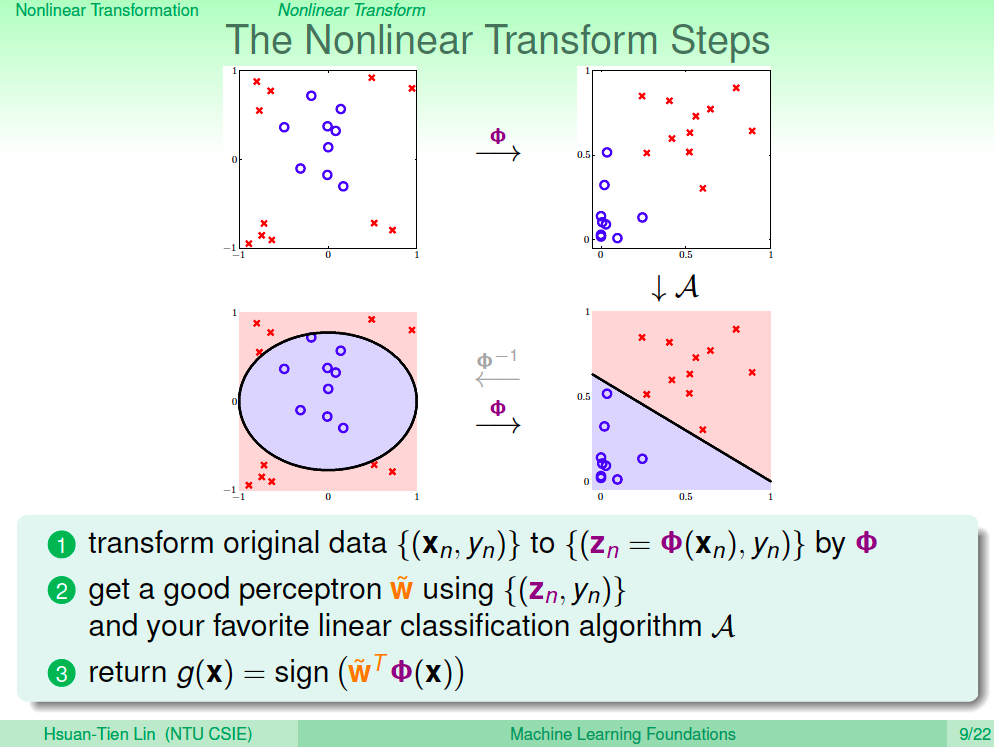
使用 QP Solver 你就可以解第一個學會的 SVM,這個 SVM 是 hard margin(需要訓練資料線性可分),且學習出來的是線性模型,如果要做非線性模型,只要將資料做非線性轉換就可以了。

探討一下其中的理論
為何胖的超平面會比較好呢?除了我們前述用例子說明之外,有沒有什麼理論基礎呢?其實如果觀察 SVM 的限制式,我們把它拿來與正規化做比較,會發現 SVM 與正規化實際上做的事情很類似,也因此兩個方法都有避免 Overfitting 的能力。

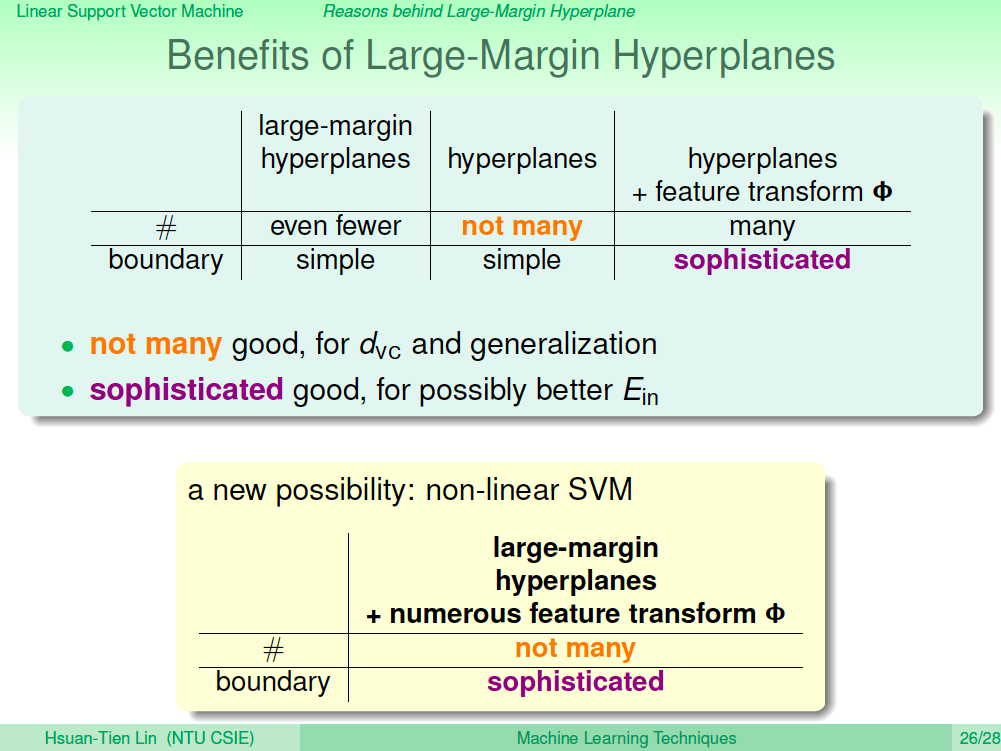
SVM 的優勢
SVM 的優勢在哪呢?之前我們學過可以將資料做特徵轉換到高維度,讓假設集合變多,可以學習更複雜的模型,但這很可能會造成 overfitting。但簡單的模型假設集合太少,無法學習複雜的模型。
我們希望可以讓假設集合不是太多,但又可以學習較複雜的模型,SVM 就可以兩全其美,他比起正規化更好的地方就在於正規化需要對原來的演算法作調整,但 SVM 本身就像是一個具備正規化的演算法。
總結
在這一講我們了解了 SVM,且知道 SVM 的特性就是去找出可以將訓練資料分好的一條最胖的超平面。而實務上我們會用二次規劃的工具來解 SVM。