
林軒田教授機器學習技法 Machine Learning Techniques 第 2 講學習筆記
前言
本系列部落格文章將分享我在 Coursera 上台灣大學林軒田教授所教授的機器學習技法(Machine Learning Techniques)課程整理成的心得,並對照林教授的投影片作說明。若還沒有閱讀過 第 1 講 的碼農們,我建議可以先回頭去讀一下再回來喔!
範例原始碼:FukuML - 簡單易用的機器學習套件
我在分享機器學習基石課程時,也跟著把每個介紹過的機器學習演算法都實作了一遍,原始碼都放在 GitHub 上了,所以大家可以去參考看看每個演算法的實作細節,看完原始碼會對課程中的數學式更容易理解。
如果大家對實作沒有興趣,只想知道怎麼使用機器學習演算法,那 FukuML 絕對會比起其他機器學習套件簡單易用,且方法及變數都會跟林軒田教授的課程類似,有看過課程的話,說不定連文件都不用看就會使用 FukuML 了。不過我還是有寫 Tutorial 啦,之後會不定期更新,讓大家可以容易上手比較重要!
熱身回顧一下
從機器學習基石課程中,我們已經了解了機器學習一些基本的演算法,在機器學習技法課程中我們將介紹更多進階的機器學習演算法。首先登場的就是支持向量機(Support Vector Machine)了,第一講中我們將先介紹最簡單的 Hard Margin Linear Support Vector Machine。
非線性 SVM
學會了 Hard Margin Linear SVM 之後,如果我們想要訓練非線性模型要怎麼做呢?跟之前的學習模型一樣,我們只要將資料點經過非線性轉換之後,在高維空間做訓練就可以了。
非線性的轉換其實可以依我們的需求轉換到非常高維,甚至可能到無限多維,如果是無限多維的話,我們怎麼使用 QP Solver 來解 SVM 呢?如果 SVM 模型可以轉換到與 feature 維度無關,那我們就可以使用無限多維的轉換了。

與特徵維度無關的 SVM
為了可以做到無限多維特徵轉換,我們需要將 SVM 轉為另外一個問題,在數學上已證明這兩個問題其實是一樣的,所以又稱為是 SVM 的對偶問題,Dual SVM,由於背後的數學證明很複雜,這門課程只會解釋一些必要的原理來讓我們理解。

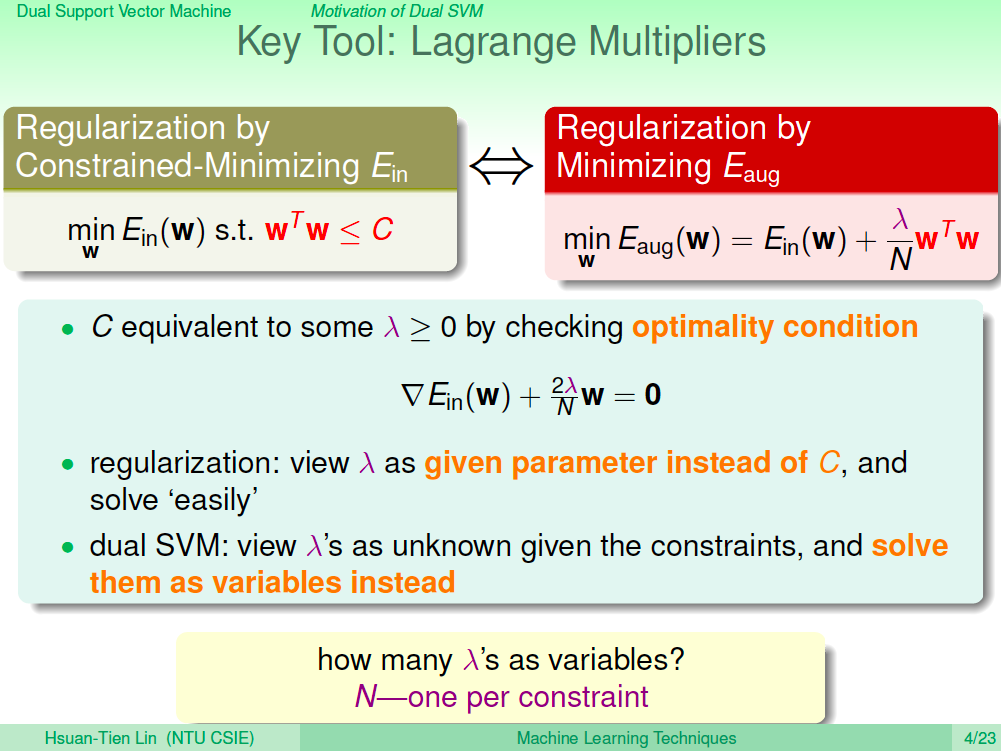
使用 Lagrange Multipliers 當工具
我們在正規化那一講中曾經使用過 Lagrange Multipliers 來推導正規化的數學式,在推導 Dual SVM 也會使用到 Lagrange Multiplier。
將 SVM 的限制條件轉換成無限制條件
在以往的課程中,我們已經了解有限制條件時,會造成我們找最佳解的困難,所以第一步我們先想辦法把 SVM 的限制條件轉換成無限制條件看看。
有了這樣的想法,我們把原本 SVM 的數學式改寫成一個 Lagrange Function,如下圖所示,原本的 N 的限制式改成了 1-yn(wTZn + b),並用 N 個 Lagrange Multiplier 來做調整(N 個 alpha)。
數學需要證明 SVM 會等於 min (max Largrange Function, all alpha >= 0),我們可以先看一下 Largrange Function 的意涵。我們希望 SVM 可以完美的分好資料,所以 1-yn(wTZn + b) 應該都是 <= 0,假設現在 1-yn(wTZn + b) 有一些正值的話,那 max Largrange Function 就會趨向無限大,所以如果我們找到正確的 b, w 分好資料,那 max Largrange 就會趨向 1/2wTw,這樣加上前面的 min,就可以知道 Lagrange Function 的轉換解出來的答案會跟原本的 SVM 一樣。

Max Min 做交換
由於 Lagrange 對偶性質,Max Min 可以透過下圖的關係式做調換,原本的 min(max Lagrange Function) 有大於等於 max(min Lagrange Function) 的關係,在 QP 的性質上,其實又說兩邊解出來的答案會一模一樣。(這邊用單純的說明,沒有數學推導證明)

解 Lagrange Dual (1)
導出目前的 Lagrange Dual 式子 max(min Lagrange Function)之後,我們要來解看看最佳解了。由於 min Lagrange Function 是沒有限制條件的,所以我們可以用偏微分來求極值。
首先我們對 b 做偏微分,會得到 - sigma(anyn) =0,負號可以不用管,所以寫成 sigma(anyn) = 0。
將這個限制式代入原本的式子,就可以把原本的式子做一些簡化,如下圖所示。

解 Lagrange Dual (2)
接下來我們對 wi 做偏微分,可以得到 w = sigma(anynzn),一樣將這個限制式代入原本的式子,原本式子中的 w 就都可以換掉。

KKT Optimality Conditions
將過這些最佳換轉換的式子,導出了一些限制式:
- yn(wTZn + b)>= 1,這是原本要將資料分好的限制式
- an >= 0,對偶問題 Lagrange Multiplier 的條件
- sigma(ynan) = 0,w = sigma(anynzn),這是最佳解時會有的條件
- 在最佳解時,an(1-yn(wTZn + b)) = 0
這就是著名的 KKT Optimality Conditions,目前這些 b,w 最佳解時的限制式,其中的變數就只剩下 an,所以實務上我們就要去找出最佳解時的 an 會是什麼,再利用上述的關係解出 b, w。

Dual SVM
導出最佳解時的所有限制式之後,原來的式子可以改成下圖中的式子,這個式子其實也是一個 QP 問題,我們可以用 QP Solver 來解出最佳解時的 an。

用 QP Solver 解 Dual SVM
我們可以用 QP Solver 解 Dual SVM,造上一講的做法去將 QP Solver 所需要的參數找出來,會有下圖中的參數。相等關係的限制式可以改成一個 >= 及 一個 <= 的關係,如果你所使用的 QP Solver 有提供相等關係的參數,那就不用這樣做。

特殊的 QP Solver
找出 Dual SVM 的所有 QP Solver 所需參數之後,我們就可以將參數丟進去 QP Solver 讓它幫忙解出最佳解。由於其中的 Q 參數可能會很大,因此使用有對 SVM 問題做特殊處理的 QP Solver 會比較沒問題。

找出最佳的 w , b
機器學習演算法最終就是要找出最佳的 w, b 來做未來的預測,不過現在 QP Solver 解出來的只有最佳解時的 an,我們要怎麼求出最佳解時的 w, b 呢?從 KKT Optimality Conditions 我們可以找出 w, b,w =sigma(anynzn) 這個條件可以算出 w,an(1-yn(wTZn + b)) = 0 這個條件可以算出 b,因為 an 通常會有大於 0 的情況,所以 1-yn(wTZn + b) 等於 0 才能符合條件,所以 b =yn - wTZn。
由於 an 大於 0 的點才能算出 b,這些大於 0 的 an 的資料點其實就是落在胖胖的邊界上。

Support Vector 的性質
由於 w = sigma(anynzn),所以其實也只有 an 大於 0 的點會影響到 w 的計算,b 也是只有 an 大於 0 時才有辦法計算,所以 an 大於 0 的資料點其實就是 Support Vector。
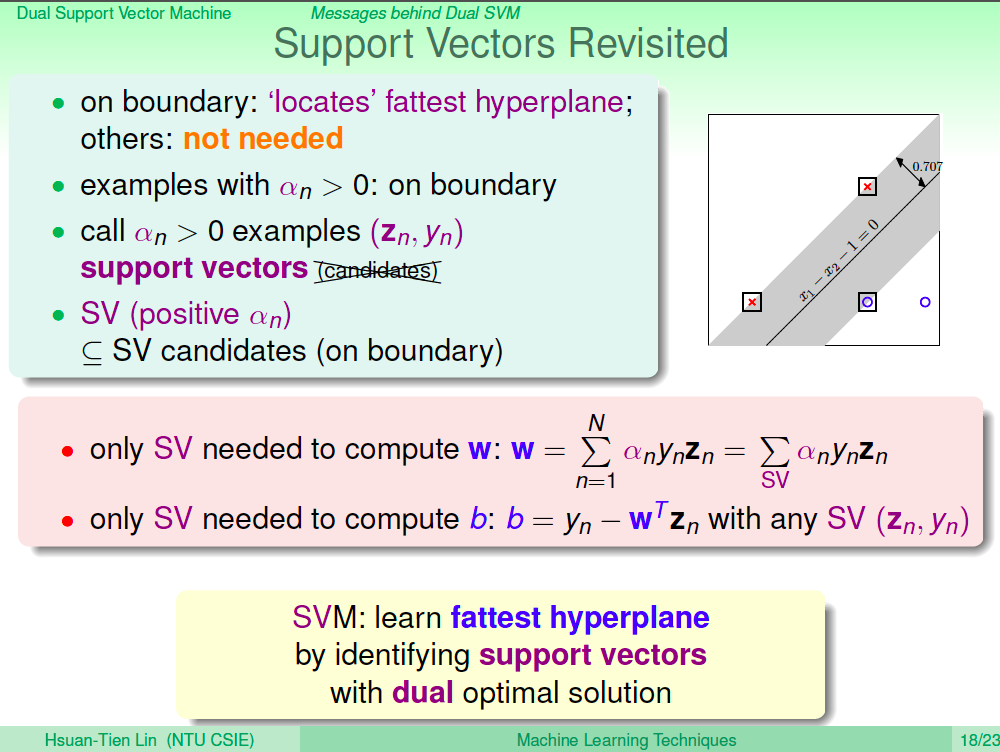
Support Vector 可以呈現胖胖的超平面
我們來看看 w = sigma(anynzn) 的含義,其實他的意思就是 w 可以被 Support Vecotr 線性組合呈現出來。這跟 PLA 也有點像,PLA 的 w 含義是被它犯錯的點的線性組合呈現出來。其實在 Logistic Regression 及 Linear Regression 也可以找到類似的性質,簡而言之,我們最後來出來做預測的 w 其實都可以被我們的訓練資料線性組合呈現出來。

比較一下 Primal 及 Dual SVM
我們將 Primal 及 Dual SVM 的式子放在一起比較,其實可以發現 Dual SVM 與資料點的特徵維度 d 已經沒有關係了,因此可以做很高維度的特徵轉換。

但其實 Dual SVM 只是把特徵維度藏起來
但其實仔細一看 Dual SVM 只是把特徵維度藏起來,在計算 Q 時,就會與特徵維度牽扯上關係,這樣就還是無法做無限維度的轉換,我們如何真正不需要計算到高維度特徵呢?這是下一講的課程了。

總結
在這一講中,我們介紹了 Dual SVM,這是為了讓我們可以對資料點做高維度的特徵轉換,這樣就可以讓 SVM 學習更複雜的非線性模型,但我們又不想要跟高維度的計算牽扯上關係,Dual SVM 將問題作了一些轉換,算是把高維度的計算藏了一半,另一半就是下次的課程了。


