林軒田教授機器學習基石 Machine Learning Foundations 第 16 講學習筆記
前言
本系列部落格文章將分享我在 Coursera 上台灣大學林軒田教授所教授的機器學習基石(Machine Learning Foundations)課程整理成的心得,並對照林教授的投影片作說明。若還沒有閱讀過 第十五講 的碼農們,我建議可以先回頭去讀一下再回來喔!
範例原始碼:FukuML - 簡單易用的機器學習套件
我在分享機器學習基石課程時,也跟著把每個介紹過的機器學習演算法都實作了一遍,原始碼都放在 GitHub 上了,所以大家可以去參考看看每個演算法的實作細節,看完原始碼會對課程中的數學式更容易理解。
如果大家對實作沒有興趣,只想知道怎麼使用機器學習演算法,那 FukuML 絕對會比起其他機器學習套件簡單易用,且方法及變數都會跟林軒田教授的課程類似,有看過課程的話,說不定連文件都不用看就會使用 FukuML 了。不過我還是有寫 Tutorial 啦,之後會不定期更新,讓大家可以容易上手比較重要!
熱身回顧一下
在上一講中,我們了解了如何使用 Cross Validation 來幫助我們客觀選擇較好的模型,基本上機器學習所有相關的基本知識都已經具備了,這一講是林軒田老師給的三個錦囊妙計,算是一種經驗分享吧~

第一計 奧卡姆剃刀
資料的解釋應該要越簡單越好,我們應該要用剃刀剃掉過分的解釋,據說這句話是愛因斯坦說的。
如下圖,我們在使用機器學習時,也希望學習出來的模型會是左較簡單的模型。在直覺上我們會覺得左圖會比右圖夠有解釋性,當然理論上也證明如此了。

較簡單的模型
什麼是叫簡單的模型呢?較教簡單的模型,就是看起來很簡單,假設較少、參數較少,假設集合也比較好。

簡單比較好
那為什麼簡單會比較好呢?除了之前數學上的解釋之外,我們可以有這樣直觀的解釋:如果一個簡單的模型可以為數據做一個好的鑒別,那就代表這個模型的假設很有解釋性,如果是複雜的模型,由於它永遠都可以把訓練資料分的很好,這樣其實是沒有什麼解釋性的,也因此用簡單的模型會是比較好的。
所以根據這一計的想法,我們應該要先試線性模型,然後盡可能了解自己是不是已經盡可能地用了簡單的模型。

第二計 避免取樣偏差
取樣有可能會有偏差,VC 理論其中的一個假設就是訓練資料與測試資料要來自於同一個分佈,否則就無法成立。如果取樣有偏差,那機器學習的效果就會不好。

處理取樣偏差
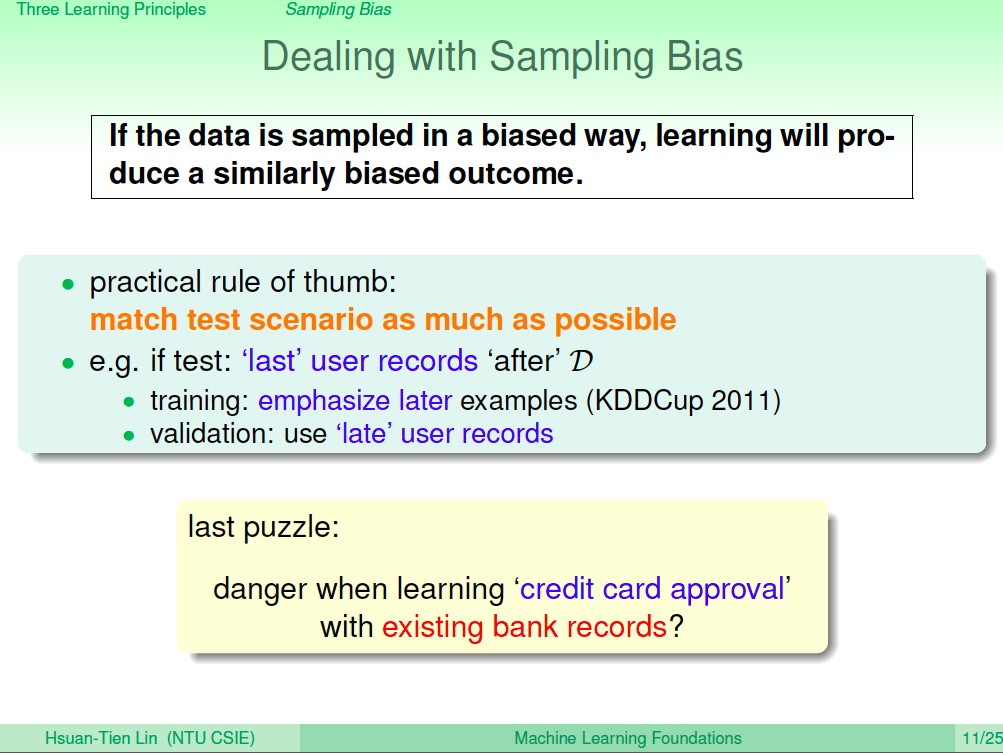
要避免取樣偏差,要好好了解測試環境,讓訓練環境跟測試環境可以儘可能接近。舉例來說,如果測試環境會使用時間軸近期的資料,那訓練時要想辦法對時間軸較近的資料做一些權重的調整,在做 Validation 的時候也應該要選擇時間軸較近的資料。
另一個例子,其實信用卡核卡問題也有取樣偏差的風險,因為銀行只會有錯誤核卡,申請人刷爆卡的記錄,卻沒有錯誤不核卡,但該位申請人信用良好的資料。因此搜集到的資料本身就已經有被篩選過了,也因此可以針對這個部分在做一些優化。
第三計 避免偷看資料
之前我們的課程中有說過,我們可能會因為看過資料而猜測圈圈會有最好的效果,但這樣就會造成我們的學習過程沒有考慮到人腦幫忙計算過的 model complexity,所以我們要避免偷看資料。

資料重複利用地偷看
其實使用資料的過程中,我們就不斷地偷看資料,甚至看別人論文時,也是在累積偷看資料的過程,所以需要了解到這個概念,有可能讓你的機器學習受到影響。

處理資料偷看
實際上偷看資料的情況很容易發生,要做到完全不偷看資料很難,所以我們可以做的就是,一開始就將測試資料鎖起來,學習的過程中完全不用,然後使用 Validation 來避免偷看資料。
如果說希望將自己的 Domain Knowledge 加入假設,應該一開始就加進去,而不是看完資料再加進去。然後,要時時刻刻會實驗的結果存著懷疑之心,要有一種感覺這樣的結果可能受到的資料偷看污染的影響。

Power of Three
除了三個錦囊妙計,林軒田老師將機器學習的重點整理成 Power of Three,帶我們整個回顧一下。
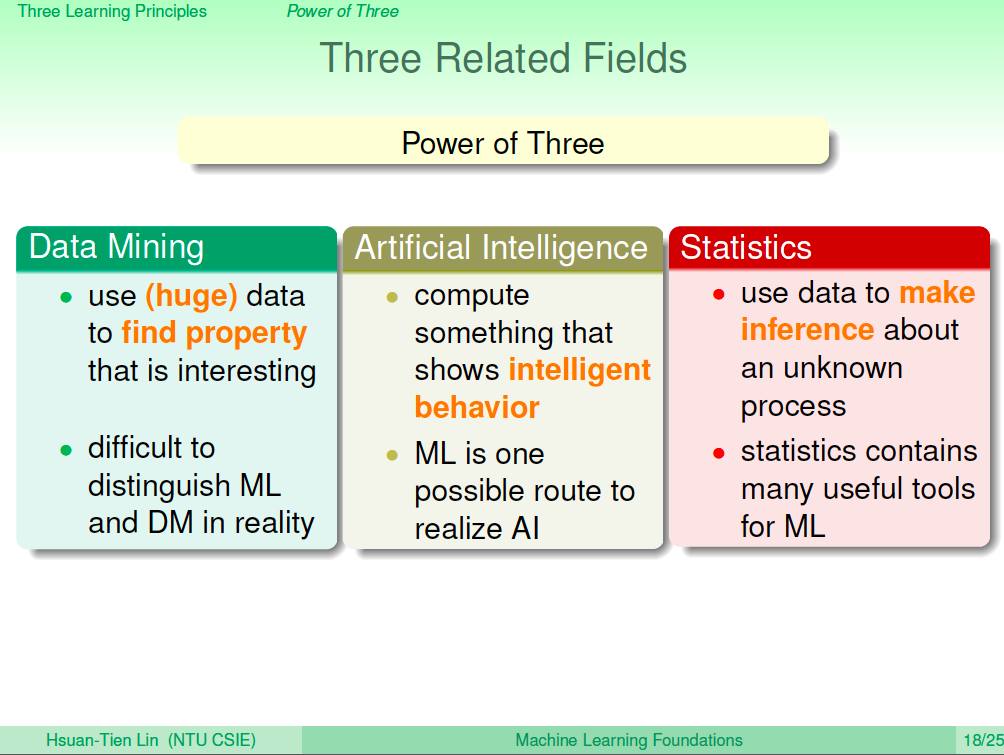
第一個是機器學習有三個相關領域,Data Mining、Artificial Intelligence、Statistics。
- Data Mining 是從大量的數據裡面找出有趣的特性,它跟 ML 是高度相關的。
- Artificail Intelligence 是想讓機器做一些有智慧的事,ML 是實現 AI 的一種工具。
- Statistics 是從數據裡做一些推論的動作,是 ML 的一種工具。
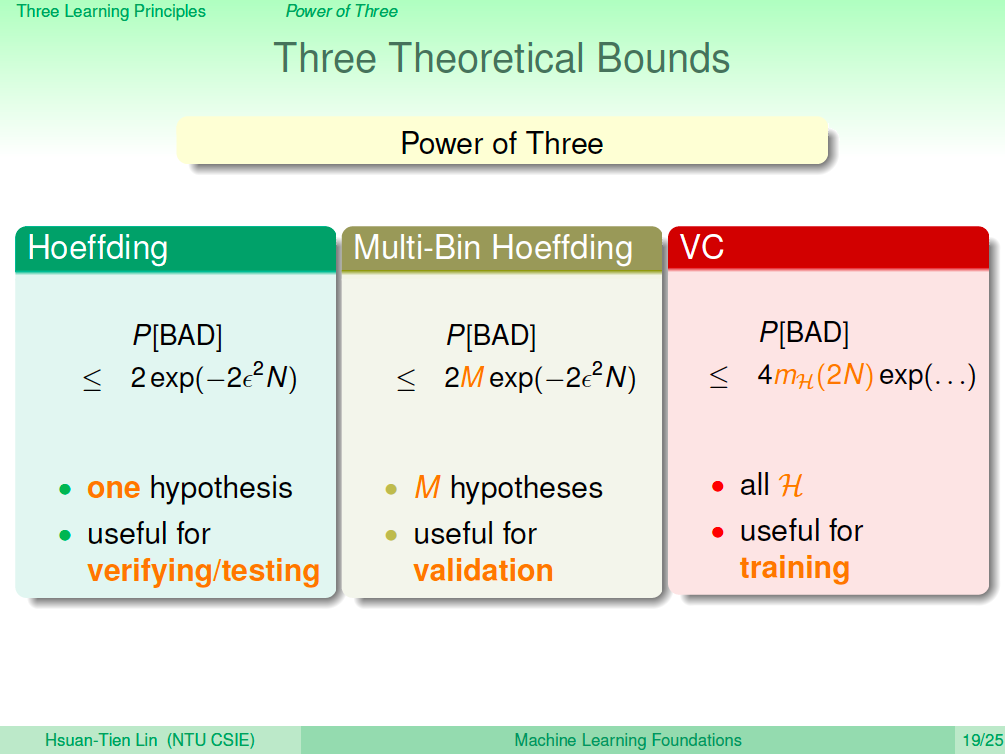
三個理論保證
- Hoeffding 不等式,針對單一個 hypothesis 保證錯誤率在某個上界,我們會用在 Testing。
- Multi-Bin Hoeffding,針對 M 個 hypothesis 保證錯誤率在某個上界,我們會用在 Validation。
- VC Bound,針對所有的 hypothesis set 保證錯誤率在某個上界,我們會用在 Training。
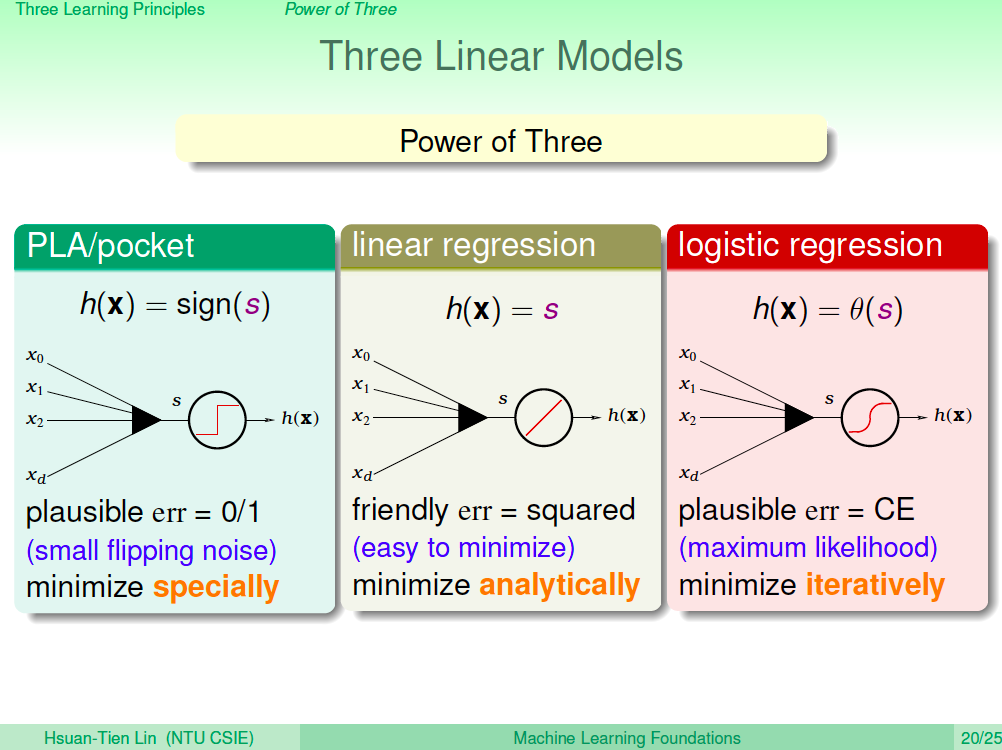
三個模型
- PLA/Pocket,用在二元分類,由於是 NP-Hard 的問題,我們使用特殊的方法來優化。
- Linear Regression,線性迴歸很容易優化,可以用公式解。
- Logistic Regression,用來計算機率,使用遞迴的方式優化。
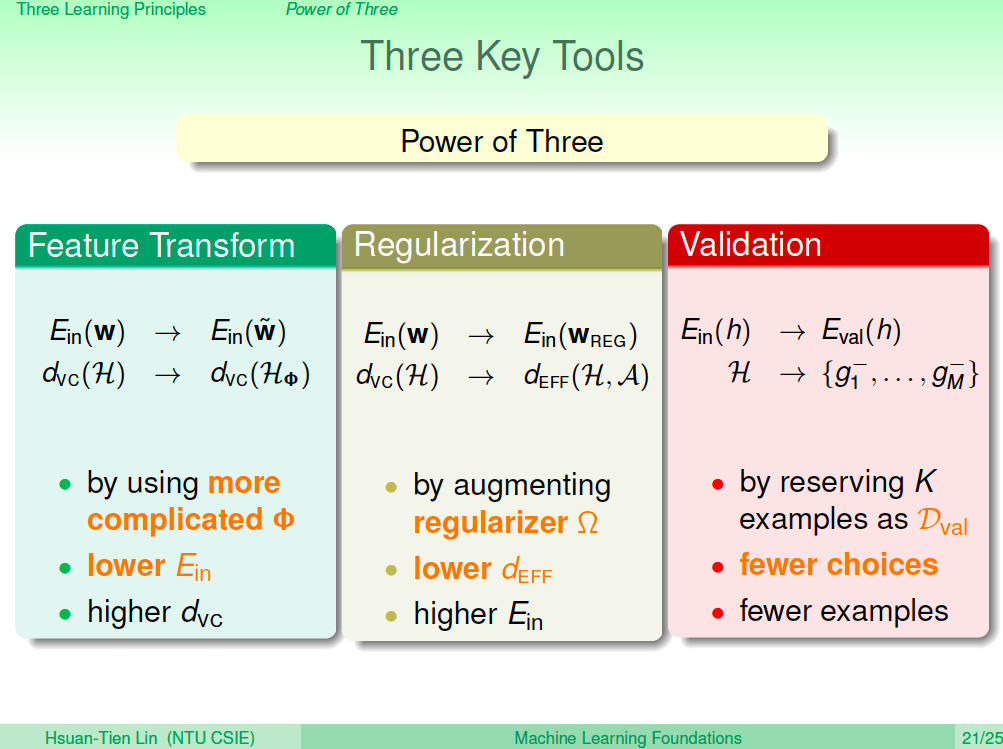
三個重要工具
- Feature Transform,可以轉換到高維空間,將 Ein 變小。
- Regularization,與 Feature Transform 相反,讓模型變簡單,VC Dimenstion 變小,但 Ein 會變大。
- Validation,留下一些乾淨的資料來做模型的選擇。
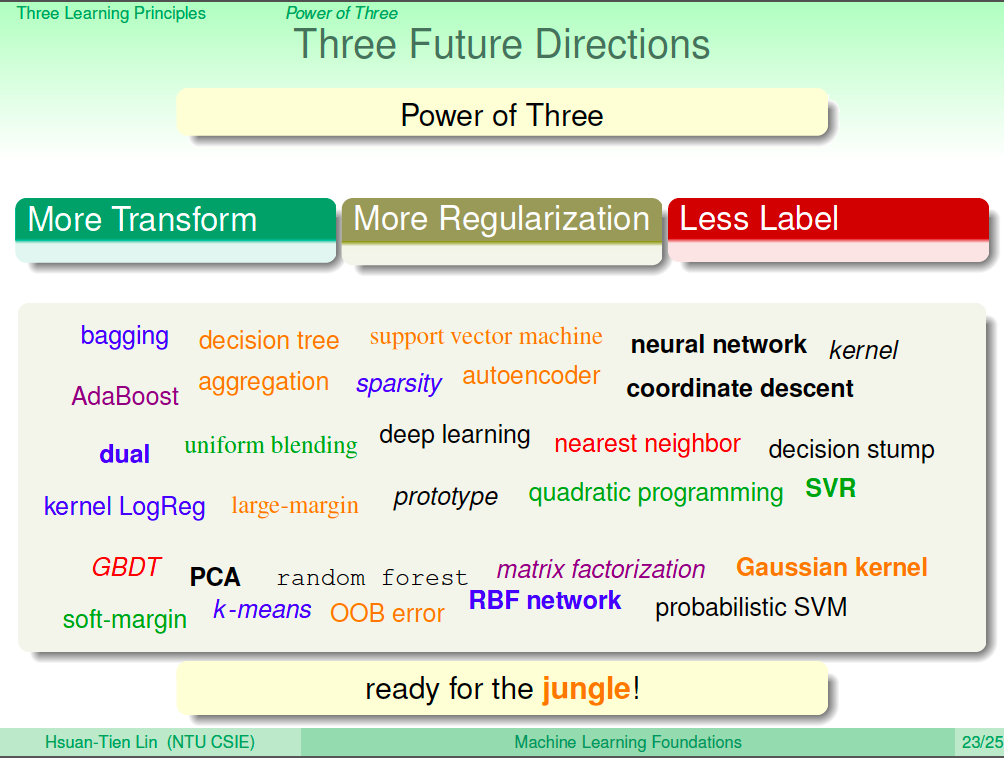
未來的方向
底下所有機器學習相關的關鍵字都是未來可以去學習的,將在後續的機器學習技法課程中講解。大致上有三個方向,一個是更多不一樣的轉換方式,不只有多項式的轉換;一個是更多的正規化方式;最後一個是沒有那麼多的 Label,比如說無監督式的學習等等。